
AIOps Use Cases for Infrastructure Cost Optimization at Scale
Amit Eyal Govrin

TL;DR
- AIOps platforms help optimize cloud and infrastructure spend through intelligent scaling, anomaly detection, and automation.
- Key use cases include dynamic resource allocation, idle resource cleanup, workload placement, and multi-cloud cost governance.
- AI-driven observability reduces the noise from monitoring tools and enables faster remediation of cost-causing incidents.
- Enterprises are already seeing 20–30% reduction in cloud bills with AIOps-based automation.
When cloud adoption exploded in the past decade, nobody warned teams about the “invisible tax” that scale would introduce. Engineers were promised flexibility, speed, and elasticity, but not the part where someone forgets to turn off a dev cluster over the weekend and burns through $3,000 before Monday. As cloud-native infrastructure matured, the cost problem grew exponentially. Teams moved fast, but so did their bills.
Now, large-scale environments come with thousands of moving parts, compute nodes, ephemeral storage, multi-cloud configurations, pipelines triggering 24/7. And with this complexity, the visibility problem has become a financial problem. According to Gartner, enterprises that implement AIOps for infrastructure optimization see up to a 30% reduction in operational and cloud costs. This isn’t just about better monitoring, it’s about intelligent automation that connects dots humans simply can’t at scale.
In this article, we’ll break down real-world AIOps use cases specifically aimed at reducing infrastructure costs at scale. We’ll look at how AIOps helps optimize resource usage, detect waste, automate savings opportunities, and enforce budget-conscious policies, all without relying on brittle scripts or static thresholds. Whether you're managing Kubernetes clusters, multi-cloud workloads, or hybrid infrastructure, this piece will give you a grounded, code-adjacent understanding of how AIOps can actually reduce your monthly bill. Below are the best use cases for Infrastructure cost optimization at scale.
Intelligent Resource Scaling Without Predefined Thresholds
Traditional autoscaling works on fixed thresholds, scale up if CPU > 80%, scale down if memory < 40%. But what if 80% isn’t always “bad”? Maybe your machine learning model is running inference, and 80% is perfectly fine. AIOps goes beyond threshold-based logic and uses historical patterns, user behavior, and seasonal workloads to scale more intelligently.
Imagine a CI/CD pipeline that typically spikes at 9 AM every Monday due to developer check-ins. AIOps tools learn this behavior over time and start provisioning compute minutes before the spike happens, not after it's already lagging. Similarly, it knows when teams go quiet (like weekends) and can proactively downscale resources without manual scripts.
This behavioral scaling drastically reduces overprovisioning. Instead of padding every workload with “just-in-case” resources, AIOps systems operate with confidence, backed by telemetry and model-driven forecasts. It’s like hiring a predictive DevOps assistant who knows what your infra will need before you even wake up.
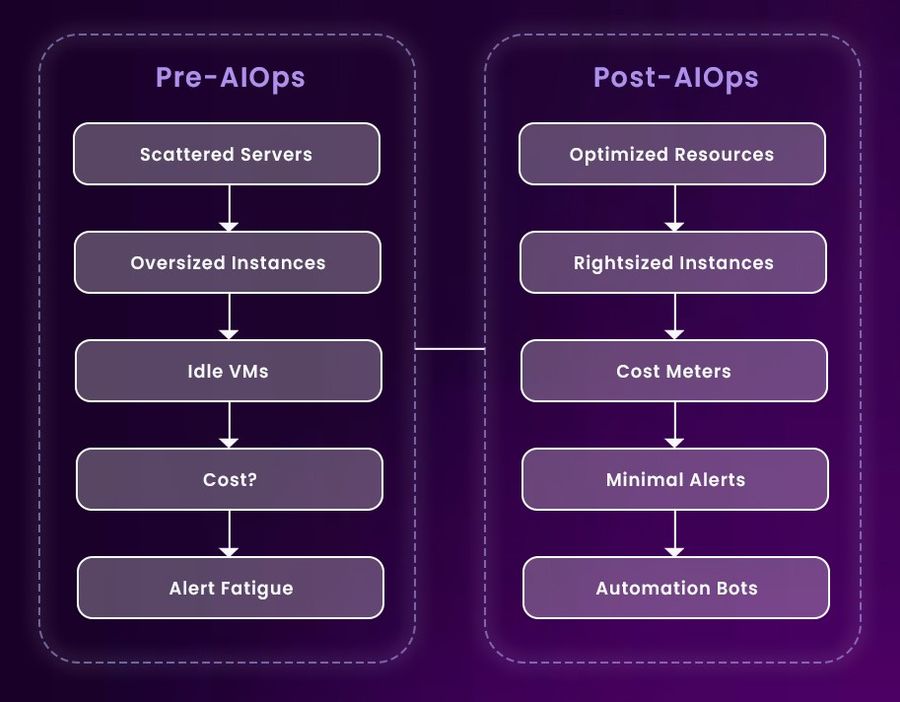
Automated Idle Resource Cleanup Across Accounts and Clouds
Idle resources are like open tabs in your browser, easy to ignore until your machine slows down. In infrastructure, they’re more expensive. Think zombie EC2 instances, forgotten staging volumes, dangling Kubernetes pods, or orphaned load balancers. While most teams intend to clean them, it rarely makes it to the sprint board.
AIOps platforms excel at discovering these invisible money leaks. They continuously crawl your infrastructure using tags, usage telemetry, and resource relations. For example, if a volume hasn’t seen any IO in 14 days and isn’t attached to a running node, it flags it for deletion or schedules it for shutdown after confirmation.
The best part? This isn’t just static rule-matching. AIOps platforms use probabilistic models to separate truly idle assets from temporarily paused ones. They can also recommend retention actions based on workload criticality or business hours, reducing false positives and ensuring that cleanup doesn’t accidentally kill something critical.
Context-Aware Workload Placement for Spot and Reserved Instances
Spot instances are cheap, but they come with a catch, they can disappear anytime. Reserved instances are stable, but you’re locked in. Without context, it’s hard to decide which workload should go where. This is where AIOps becomes useful beyond monitoring, it becomes a placement engine.
AIOps tools analyze workload characteristics, how long they run, whether they tolerate interruptions, CPU/memory patterns, and even security/compliance needs. Based on this, they automatically tag jobs as “spot-friendly” or “reserved-worthy” and shift them across instance types dynamically.
For example, short-lived batch jobs or video encoding pipelines can be routed to spot instances, while backend services with steady traffic get mapped to reserved infrastructure. Over time, this pattern-driven optimization yields significant cost savings, especially for workloads at scale. And unlike humans, AIOps doesn’t forget to rebalance when usage patterns change.
Cross-Environment Rightsizing Based on Real-Time Utilization
Rightsizing is the practice of adjusting resource allocation to fit actual usage. But in most teams, it’s either ignored or done quarterly because the tooling and effort involved is massive. AIOps simplifies this by making it continuous and cross-environmental.
Instead of relying on static cloud billing reports, AIOps systems plug into telemetry sources like Prometheus, CloudWatch, Datadog, etc. They build real-time profiles of how resources behave, not just in one cluster, but across dev, staging, and production. Then they offer precise recommendations: downgrade a node from m5.4xlarge to m5.2xlarge, or switch a Kubernetes deployment to use requests=300Mi instead of 500Mi.
This right-sizing isn’t limited to infrastructure, AIOps platforms can also track container utilization, database query patterns, and storage access frequency. Over time, the system becomes a rightsizing oracle that ensures you’re not spending $1,200/month to run a job that needs $400.
AI-Driven Forecasting to Prevent Budget Overruns
Budget alerts often show up after the damage is done, “You’ve exceeded your monthly AWS budget by $4,000.” By then, it’s too late to reverse anything. AIOps introduces proactive cost forecasting based on usage trends, not just limits.
By consuming billing data and pairing it with real-time utilization, AIOps engines can predict next month’s costs with alarming accuracy. They factor in team velocity, traffic growth, and seasonal patterns. For example, an AIOps platform may detect an unusual spike in latency on a specific API, signaling a potential failure. It can recommend preventative actions, such as scaling compute resources or reviewing the latest deployment. This kind of insight is invaluable for sectors like finance or healthcare, where downtime can mean significant financial and reputational losses.
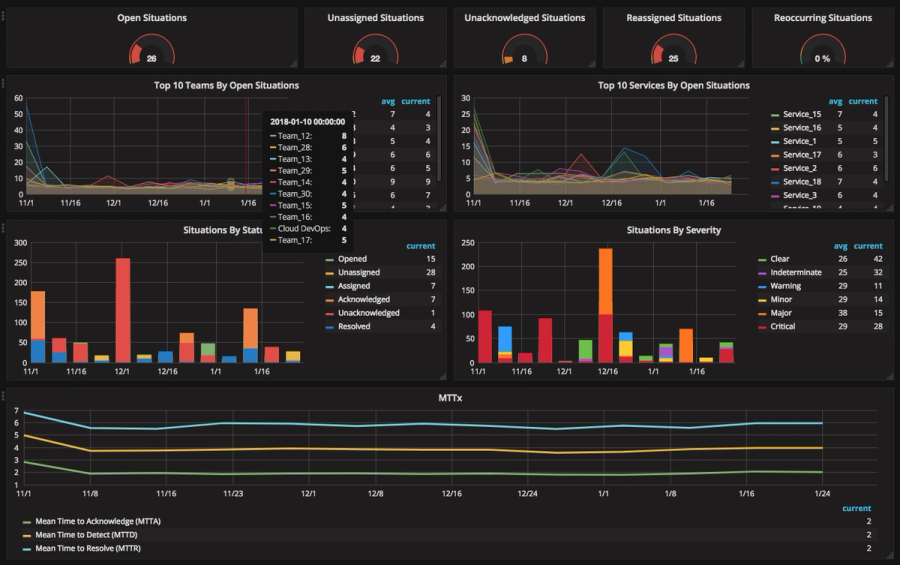
Source: Moogsoft
What The Dashboard Shows
- Top-level gauges highlight current incident volume:
- 26 open situations, 22 unassigned, 8 unacknowledged — indicating backlog.
- 25 reassigned alerts suggest frequent handoffs; 0% reoccurring is a good sign of lasting resolutions.
- Top 10 Teams by Open Situations shows workload distribution:
- Teams like Team_12, Team_28, and Team_13 are handling more issues.
- Helps identify overloaded teams or ownership gaps across dates.
- Top 10 Services by Open Situations surfaces noisy or problematic services:
- Services 15, 16, 1, and 17 had multiple persistent alerts.
- Useful for pinpointing high-cost or unstable infrastructure components.
- Situations by Status tracks incident lifecycle:
- A spike in unassigned and unresolved alerts around 12/1 hints at a delayed response window.
- Indicates where AIOps could automate triage or escalation workflows.
- Situations by Severity prioritizes risk:
- A major spike in Major and Critical issues around 12/16 suggests a system-wide incident or outage.
- Severity mapping helps teams focus on alerts with actual business or cost impact.
- MTTx Graph (Mean Time Metrics) gives insight into operational efficiency:
- MTTA, MTTD, and MTTR are relatively stable, around the 5–6 hour mark.
- Consistency is good, but still room to improve resolution speed, especially for critical incidents.
Unlike reactive approaches, AIOps takes a proactive stance that forms the foundation of modern IT resilience. Companies like Moogsoft and Aisera are already implementing these predictive AIOps solutions.
These forecasts aren't just static graphs. They come with recommendations. If forecasted storage costs are about to spike 50%, the system may suggest archiving cold data or switching to lower-tier object storage. Essentially, AIOps transforms budgeting from reactive accounting into preventative action.
Noise Reduction in Monitoring to Focus on Cost-Critical Alerts
Traditional monitoring setups are noisy, hundreds of alerts, most of them irrelevant. The real cost issues, like runaway log volumes or misconfigured autoscaling, get buried. AIOps systems clean up this mess with context and correlation.
Instead of treating every metric spike as a separate issue, AIOps clusters related symptoms into a single incident. For instance, a sudden CPU spike, increased IOPS, and rising storage costs might all be linked to a rogue deployment. AIOps shows one alert, not ten. More importantly, it tags the alert with cost relevance, how much this anomaly is costing you per hour.
This changes how teams triage incidents. Instead of being flooded by CPU threshold breaches, they focus on the ones that have an actual dollar impact. With fewer alerts and more context, SREs and DevOps teams spend less time chasing phantom issues and more time fixing real ones.
Intelligent Automation of Runbooks to Optimize Infra in Real Time
Most cost-saving decisions require someone to do something, scale down a cluster, terminate a job, tweak resource configs. AIOps goes beyond suggestions by triggering automation based on predefined policies and real-time analytics.
These automations are often encoded as runbooks or workflows. For example, if memory usage stays below 30% for an hour, AIOps might trigger a workflow to reduce the number of replicas. Or if unused storage grows beyond 500 GB, it may kick off an archiving job. These aren’t just scheduled cron jobs, they’re adaptive automations, triggered by context, not time.
Over time, the automation library becomes richer. The system begins to act like a cost-saving co-pilot, executing safe actions with confidence and escalating edge cases for review. It’s not just about saving engineering time, it’s about keeping infra spend under control even when no one is watching.
Cost-Conscious CI/CD: Optimizing Builds, Tests, and Deployments
CI/CD pipelines sometimes become wasteful. Large builds run on oversized agents, tests trigger across multiple platforms even when not needed, and preview environments stay up long after a PR is closed. AIOps tools can inject cost-awareness directly into your DevOps toolchain.
By analyzing build duration, parallelism, and flakiness, AIOps can suggest better caching strategies, merge test steps, or even auto-prioritize critical test cases. For example, if integration tests rarely fail but cost 4x more than unit tests, the system may recommend a different trigger strategy or on-demand parallelism.
Similarly, AIOps can manage ephemeral environments. It detects inactivity and auto-shuts preview environments after a timeout. If multiple branches are triggering redundant builds, it merges those triggers into a single job. This optimization doesn’t just cut cloud bills, it speeds up the delivery cycle and makes CI/CD more predictable.
Policy-Driven Multi-Cloud Cost Governance
Running workloads across AWS, Azure, and GCP? Welcome to the wild west of billing. Without strict governance, teams often lose sight of who owns what, why something exists, or whether two clouds are doing the same job. AIOps brings order through policy-driven governance.
This means setting up rules like: “Dev environments must terminate after 12 hours,” or “Use spot instances unless the SLA requires otherwise.” AIOps monitors cloud usage in real time and flags, or enforces, violations automatically. These policies are codified, versioned, and auditable, much like Infrastructure-as-Code.
What makes this powerful is visibility. AIOps gives you a unified view of cloud spend across providers, broken down by service, team, or project. It helps platform teams make strategic calls, do we migrate a workload from GCP to AWS? Should we consolidate under one provider? These aren’t gut decisions, they’re made with data.
Conclusion
Optimizing infrastructure cost at scale is no longer a luxury, it’s a survival tactic for modern engineering teams. As environments get more dynamic, distributed, and automated, human intuition alone can't keep up. AIOps introduces a paradigm shift: cost optimization as a continuous, intelligent, and self-improving system.
But AIOps is not plug-and-play. It demands thoughtful integration, good telemetry hygiene, and alignment with team workflows. When implemented right, it becomes a silent operator, always watching, always learning, and always ready to nudge your infra toward better efficiency. Like a financial autopilot for your backend stack.
And perhaps the biggest win? It frees engineers from the constant anxiety of cloud bills, letting them focus on building, not budgeting.
Frequently Asked Questions
1. What role does AIOps play in optimizing IT and infrastructure costs?
AIOps applies AI-driven automation to streamline resource utilization, reduce downtime, and proactively manage infrastructure. It identifies inefficiencies, such as idle or overprovisioned resources, and automates their remediation to deliver measurable cost savings and operational value.
2. How can AIOps improve cloud operations and cost governance?
By integrating with telemetry sources (logs, metrics, events), AIOps enables intelligent autoscaling, predictive capacity planning, and enforcement of cost policies. This approach ensures optimal provisioning and real‑time cost visibility, cutting waste and aligning resources with actual usage needs.
3. What should organizations consider when choosing an AIOps platform for cost optimization?
Essential factors include the breadth of analytics and automation features, support for cost‑specific use cases, and the platform’s ability to ingest diverse data types. Domain‑specific tools for cost and capacity management are more focused and often more affordable than broad, data‑agnostic solutions.
4. What types of cost efficiencies and ROI can organizations expect from AIOps?
Organizations leveraging AIOps in cloud and infrastructure operations typically report 20–30% savings. These gains come from improved resource utilization, reduced human error, predictive remediation of issues, and automated governance that prevents cost overruns.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
