
AIOps vs MLOps for DevOps Engineers: What You Really Need to Know
Amit Eyal Govrin

TL;DR
- AIOps uses AI/ML to reduce alert noise, automate incident workflows, and predict system issues before they escalate.
- MLOps manages the full lifecycle of machine learning models, from training to deployment and production monitoring.
- DevOps engineers are more directly involved in AIOps, while MLOps intersects with data science workflows.
- Gartner estimates that by 2027, 50% of enterprises will integrate AIOps into their observability stack.
- Use AIOps to scale infrastructure management intelligently; adopt MLOps when ML models become a production concern.
It Doesn’t Start with Buzzwords, It Starts with Bottlenecks
AIOps and MLOps don’t exist because of tech hype. They were born out of growing friction in real teams. When infrastructure scales beyond human operability, or when machine learning efforts break down at deployment, teams look for structured ways to recover velocity. That’s what makes these disciplines essential, they solve bottlenecks, not buzzword checklists.
AIOps emerges from the chaos of infrastructure. In modern systems, it’s not uncommon for teams to get hit with thousands of alerts daily, most of which are false positives, duplicates, or irrelevant. SREs end up firefighting symptoms without clarity on the root cause. This noise fatigue leads to burnout and slow incident response. AIOps flips that script: it applies ML algorithms on telemetry to correlate, deduplicate, and triage issues, often before a human even looks at them.
MLOps, by contrast, addresses an entirely different pain. When data scientists build models, they often work in isolation from deployment environments. The model may work great locally, but fall apart in production due to unseen data skews, latency constraints, or versioning issues. MLOps brings the discipline of CI/CD to machine learning, creating structured workflows around training, validation, release, monitoring, and retraining. It’s not a tool. It’s a way to operationalize intelligence, not just develop it.
Core Focus: Automation of Ops vs. Productization of ML
At its heart, AIOps is an evolution of classic observability, but enhanced with intelligent automation. It’s not trying to replace engineers; it's trying to give them better signal-to-noise ratios. Instead of manually digging through logs and metrics, AIOps platforms surface patterns: “This spike in CPU? Correlated with that degraded database pod and increased 5xx errors.” Think of it as turning observability into actionable diagnostics.
MLOps has a very different mission. Its job is to bridge the massive gap between data science experimentation and live product deployment. Without MLOps, models tend to become brittle artifacts that work in one environment and break in another. MLOps enforces repeatability, versioning datasets, tracking experiments, automating tests, and ensuring that models deployed to prod have lineage, explainability, and rollback paths.
You can think of AIOps as your real-time AI-powered sidekick in ops, always watching and learning from system behavior. MLOps, on the other hand, is like a factory assembly line for models, ensuring that what you build in training is what users experience in prod. While both use AI/ML techniques under the hood, their purpose, pipeline, and impact are completely different.
Who Owns What: DevOps, SREs, and ML Engineers in the Loop
Ownership is often the clearest signal of how different these two paradigms are. AIOps falls squarely within the domain of DevOps engineers and SREs, because it's built around infrastructure telemetry. It integrates into logging, monitoring, alerting, and remediation systems, the bread and butter of modern operations teams. From setting up anomaly detectors to defining auto-remediation scripts, the AIOps loop is deeply infra-native.
MLOps workflows are typically triggered by ML engineers or data scientists, who own model training, data pipelines, and experimentation. But the moment these models need to scale in production, say, running inference across thousands of requests per second, DevOps and platform engineers step in. They manage GPU scheduling, container orchestration, deployment automation, and security. MLOps is inherently cross-functional, which is why ownership often becomes fragmented without clear handoffs.
In mature organizations, these boundaries are becoming more fluid. Platform teams are being formed to abstract away infra concerns for both MLOps and AIOps use cases. But in most cases today, DevOps engineers will encounter AIOps first, especially when trying to reduce incident response time, alert fatigue, and manual playbooks.
Data Inputs: Different Feeds, Different Needs
One of the least discussed, but most defining differences between AIOps and MLOps is the nature of the data they consume. AIOps feeds on telemetry data, logs, metrics, traces, events. This data is continuous, high-frequency, and often semi-structured. It comes from thousands of sources across your systems: containers, nodes, databases, APIs, external services. AIOps tools must process this in near-real-time to detect anomalies and suggest remediations.
MLOps, on the other hand, works with static or semi-static datasets, often structured and curated for training. These include labeled datasets, feature vectors, embeddings, and streaming features pulled from online feature stores. While some aspects like online inference monitoring are real-time, the training data cycle is fundamentally batch-oriented. The input is not telemetry, its historical behavior with known outcomes, used to predict future behavior.
This leads to fundamental architectural divergence. AIOps pipelines resemble real-time stream processors (Kafka, FluentBit, OpenTelemetry collectors), while MLOps pipelines often use batch schedulers and orchestrators (Airflow, Argo, SageMaker Pipelines). If you feed the wrong kind of data into the wrong pipeline, you’ll get garbage results or wasted compute, or worse, false confidence.
Tooling and Workflow: Terraform vs TFX
AIOps and MLOps each come with their own ecosystem of tools, and trying to unify them too early leads to chaos. In AIOps, the workflow is built around observability and automation tooling. You might use Prometheus and Grafana to collect and visualize metrics, but plug that into an AIOps engine like Moogsoft or BigPanda to detect anomalies. Incident routing goes through PagerDuty or Opsgenie, and Terraform or Ansible might be invoked for auto-remediation.
In MLOps, the stack looks different from the ground up. You begin with data versioning tools like DVC or LakeFS, experiment tracking with MLflow or Weights & Biases, then progress into model training with SageMaker or Kubeflow. Serving is done with KServe, BentoML, or Triton, and observability comes from tools that can track model accuracy, latency, drift, and explainability (e.g., WhyLabs, EvidentlyAI).
Even your CI/CD pipelines will diverge. AIOps ties into classic CI/CD, deploy the app, monitor it, and adjust infra automatically. MLOps often extends into CI/CT (continuous training), where a new batch of labeled data may trigger a fresh round of model training, validation, and promotion to staging. These workflows might live in Jenkins, GitHub Actions, or orchestrators like Airflow, but they are far less deterministic than traditional application pipelines.
Deployment Considerations: Observability vs Explainability
Deployment in the AIOps world means deploying rules, models, or alerting thresholds into your observability stack. The goal is to automate detection and speed up response without overwhelming humans. This requires high-quality metadata, dependency maps between services, and integrations with incident management platforms. Most of the work lies in tuning the noise floor, ensuring that alerts are meaningful and actionable.
MLOps deployments involve model artifacts, containers, and APIs. The challenge isn’t just about uptime, it’s about ensuring the model behaves correctly. That’s where explainability comes in. Tools like SHAP or LIME are often integrated into the deployment pipeline to provide transparency. Business stakeholders don’t just want to know that the fraud detection model works; they want to know why it flagged a specific transaction.
For DevOps teams used to binary success/failure deploy metrics, this probabilistic world of MLOps can be frustrating. A model with 93% accuracy may still produce dozens of false positives, and “rolling back” means restoring old model versions, not code. This difference in deployment risk models is critical to grasp before choosing your tooling or team structure.
Feedback Loops: One for Incidents, One for Models
Feedback loops are central to both AIOps and MLOps, but they operate on different timescales and signals. In AIOps, the feedback loop is immediate. A service crashes, a spike is detected, an alert fires, and remediation kicks in, possibly automatically. Logs and metrics flow back into the AIOps system to improve future triage or suggest threshold tuning. The loop is tight, reactive, and infrastructure-bound.
In MLOps, feedback loops can span days or weeks. A recommendation model might start to degrade as user behavior shifts. You only notice when click-through rates drop or business metrics start to sag. Then comes the process of data collection, retraining, validation, and re-deployment. This loop is slower, fuzzier, and harder to automate, which is why MLOps pipelines must be very robust in tracking inputs and outputs.
One analogy here is the difference between a thermostat and a weather prediction model. A thermostat senses change and responds instantly. A weather model makes probabilistic forecasts and is updated slowly based on large datasets. Both use feedback, but at fundamentally different rhythms.
Incident Management vs Model Governance
Incident management is where AIOps truly shines. Traditional incident response often looks like chaos, one engineer in logs, another on Grafana dashboards, someone else trying to kill stuck pods. AIOps tools streamline this with automated root cause analysis, context-rich alerts, and even self-healing runbooks. Instead of just alerting when the CPU crosses 80%, AIOps can say: “This is correlated with a downstream Redis cache latency spike and similar to an incident from last Thursday.” It gives engineers a head start, not just a warning.
MLOps, however, is less concerned with uptime and more focused on governance, ensuring every model is trackable, explainable, and compliant. This means rigorous versioning (of both code and data), reproducibility (same model, same output), and audit trails. In many industries, from finance to healthcare, this isn’t optional. Regulations require that decisions made by algorithms be traceable back to their training data and parameters.
In DevOps terms, it’s like the difference between incident response SLAs and security/compliance audits. AIOps helps reduce MTTR and prevent escalation. MLOps helps you prove that a model decision wasn’t biased or based on stale data. One is real-time crisis mode; the other is long-term trust and traceability.
CI/CD Integration: Predictive vs Deterministic
AIOps typically get embedded into traditional CI/CD workflows through observability gates. For example, you might run load tests post-deployment and use an ML-based detector to analyze error spikes. If anomalies are detected, the pipeline can halt or rollback automatically. The CI/CD flow remains deterministic, but it now includes predictive checkpoints powered by AI.
MLOps, on the other hand, extends the CI/CD model in both directions. It introduces data validation steps before training, model evaluation checks before release, and drift detection after deployment. In fact, the model CI/CD is often better described as CI/CT/CD, Continuous Integration, Continuous Training, and Continuous Delivery. Each phase has its own tests, gates, and logging requirements.
The difficulty arises when DevOps engineers try to plug MLOps into Jenkins or GitHub Actions the same way they do with app builds. Model deployments need special runners (often with GPUs), parallel experiments, and conditional rollouts based on business KPIs, not just test pass/fail. Understanding these constraints early prevents misaligned pipelines and flaky releases.
Adoption Curve and Team Maturity
Your team’s maturity, both in platform engineering and ML readiness, should inform whether AIOps or MLOps deserves attention first. If you’re getting paged at 2 AM for non-critical issues, spending hours sifting through Grafana panels, and manually scaling infra, AIOps will give you immediate quality-of-life improvements. You don’t need a data scientist to get started; many AIOps platforms integrate natively with existing telemetry systems.
MLOps requires more groundwork. You need good data pipelines, a clear modeling strategy, and infrastructure to support training and serving. If your ML efforts are still exploratory or confined to notebooks, jumping into MLOps too early can lead to overengineering. But if you’re shipping ML models into production, and those models are tightly coupled to user experiences, then MLOps isn’t optional, it’s survival.
It’s a mistake to assume these two need to be adopted together. Many orgs try, fail, and then backpedal. The key is to solve real pain, not chase buzzwords. AIOps is ideal for scale-hardened ops teams; MLOps is for teams shipping ML as a feature or product. Let your org’s context, not a vendor pitch, guide you.
The Real Overlap: Platform Engineering and Shared Practices
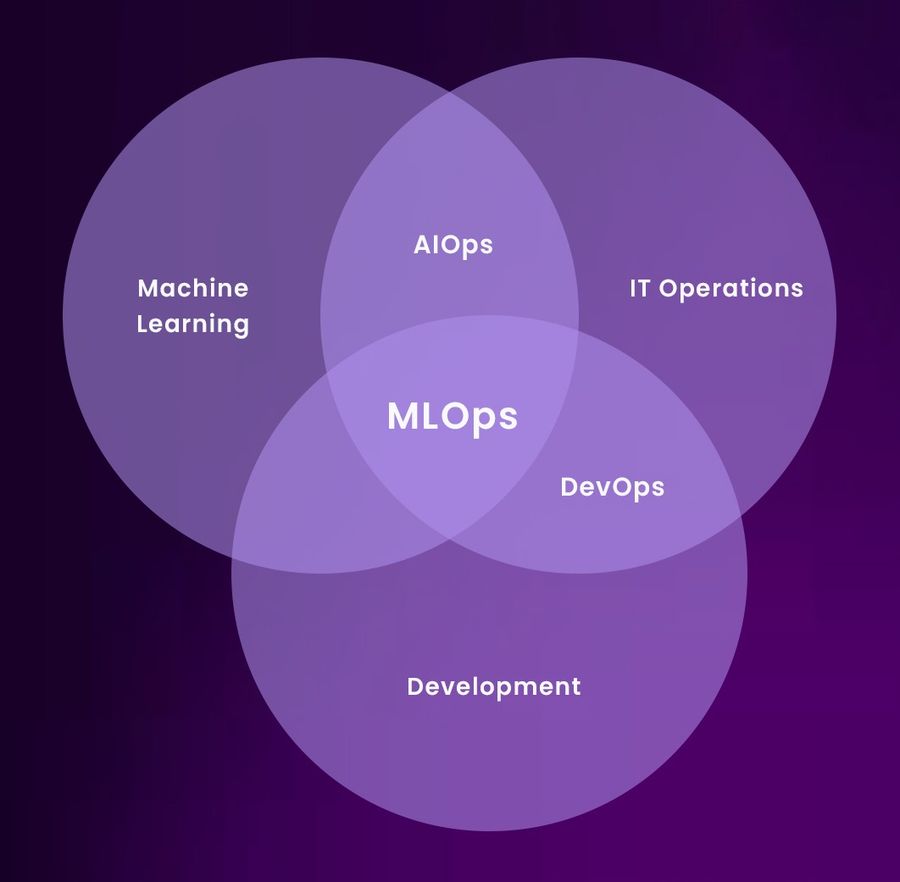
While AIOps and MLOps differ in purpose, they converge in platform engineering principles. Both benefit from strong foundations in observability, GitOps, secret management, and infrastructure-as-code. A shared platform team can enable reusable pipelines, policy-as-code frameworks, and declarative service definitions, regardless of whether the output is an ML model or a monitoring dashboard.
Kubernetes is a perfect example of this shared substrate. In AIOps, it’s the system being monitored. In MLOps, it’s often the workload runner, training jobs, inference services, and model orchestration tasks run as pods. Similarly, CI/CD pipelines written with tools like Argo or Tekton can be adapted to serve both log aggregation workflows (AIOps) and model promotion flows (MLOps).
There’s also an emerging trend of using GitOps patterns across both fields. In AIOps, this might look like storing alerting configurations or dashboards as code. In MLOps, it could mean managing model versioning or deployment manifests via Git. The goal in both cases is reproducibility, auditability, and fewer manual steps. Platform engineers become the bridge, enabling different workflows on a unified delivery backbone.
Conclusion
There’s no one-size-fits-all answer, but there is a right sequence. For most DevOps teams, AIOps offers the quickest ROI. It makes incident response faster, reduces alert noise, and brings ML benefits without needing a data science team. The barrier to entry is low, and the outcomes are tangible, shorter downtime, happier engineers, better sleep.
MLOps require a longer investment. It's worth it when you're dealing with real ML in production, recommendation engines, NLP models, vision pipelines, etc. The challenge here isn’t technical alone. It’s cultural. Data science teams need to embrace operational constraints, and DevOps teams need to understand model idiosyncrasies. Done well, MLOps becomes a flywheel that lets ML innovation scale without melting down in prod.
Eventually, both AIOps and MLOps will become normal infrastructure concerns, just like CI/CD and container orchestration did. Until then, the key is to treat them as tools to solve pain, not trends to chase. Look at your team’s bottlenecks, your systems’ fragility, and your product’s needs. Then decide: do you need fewer pages or better predictions?
FAQs
1. Is AIOps the same as MLOps?
No, they serve fundamentally different purposes. AIOps applies AI and ML to automate IT operations, focusing on anomaly detection, event correlation, and speeding up incident resolution. In contrast, MLOps streamlines the deployment and lifecycle of ML models, ensuring models are versioned, monitored, retrained, and governed reliably in production.
2. Can you implement AIOps without having MLOps?
Yes, AIOps and MLOps are independent. AIOps leverages ML to improve system reliability and operational visibility, whereas MLOps addresses the lifecycle of the models themselves. Organizations without ML models can adopt AIOps purely to enhance their IT operations.
3. When should an organization use AIOps versus MLOps, or both?
Use AIOps when the primary pain point is operational overload, noisy alerts, slow incident response, fragmented telemetry. It brings intelligence into operations workflows without requiring ML model deployment teams. MLOps becomes necessary when your team is building and deploying ML‑based features or products, needing structured pipelines for versioning, monitoring, and retraining. In mature setups, both can coexist effectively, with shared platform practices but distinct pipelines.
4. What is the primary data input difference between AIOps and MLOps?
AIOps processes real-time operational telemetry, logs, metrics, traces, events, to detect anomalies and root causes. MLOps, however, deals with training datasets, feature stores, and model artifacts aimed at building and refining predictive models. These differences influence pipeline architecture: stream processing for AIOps versus batch and orchestration workflows for MLOps.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
