
Context Engineering: Understanding With Practical Examples
Amit Eyal Govrin

TL;DR
- Context engineering is crucial for advanced AI systems, as it ensures that models receive the correct information at the appropriate time, in the most suitable format, enabling them to comprehend, retain, and apply knowledge effectively across complex tasks, rather than merely responding to one-off prompts.
- Unlike traditional prompt engineering, which focuses on providing instructions for a single task, context engineering manages multiple layers of information, including conversation history, user preferences, documents, tools, and structured outputs, allowing the AI to maintain continuity, recall relevant details, and behave intelligently over time.
- Practical context engineering techniques such as retrieval-augmented generation (RAG), context summarization, memory systems, and tool orchestration help mitigate common failures like context poisoning, context distraction, confusion, and clashes, ensuring that AI responses remain accurate, relevant, and coherent even in multi-step or long-term interactions.
- By implementing context engineering, AI systems evolve from reactive, single-task responders into adaptive, human-like collaborators that can understand project-wide dependencies, handle dynamic inputs, and provide meaningful, reliable outputs, making them capable of complex reasoning, multi-source data integration, and sustained problem-solving.
You may know how to write clever prompts, but as AI systems get more complex, they often struggle to remember important information, maintain project context, or connect data across multiple sources. Your chatbot might forget instructions, your AI assistant may lose track of the project structure, and your knowledge retrieval system may fail to link insights from different documents.
This is where context engineering comes in. As AI applications become more sophisticated, designing effective prompts is only one piece of the puzzle. Context engineering ensures that systems understand, retain, and apply relevant information, making AI smarter, more reliable, and capable of handling complex tasks.
In this blog, we will explore what context engineering is, why it matters, how it differs from regular prompt engineering, and the practical techniques you can use to make AI systems truly context-aware.
What is Context Engineering?
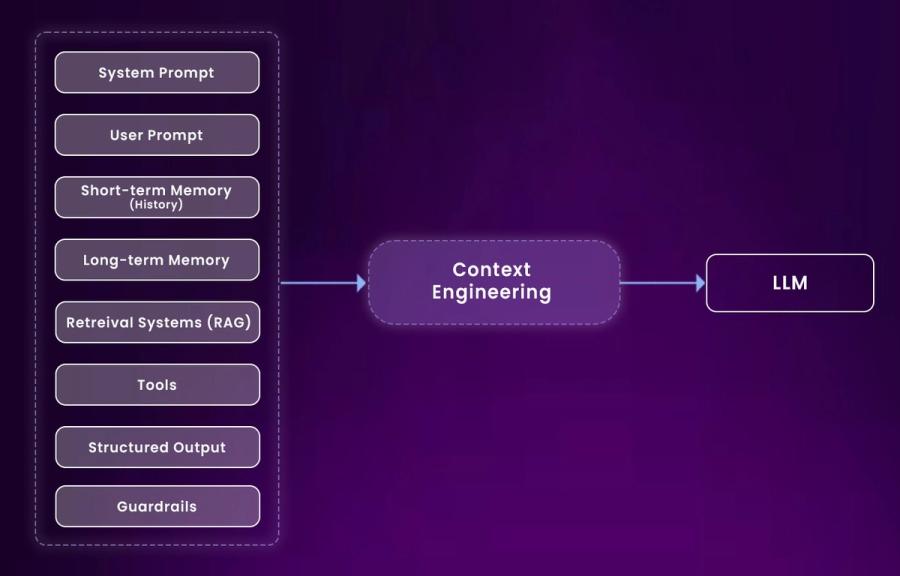
Context engineering is about ensuring an AI has access to the right information at the right time so it can provide accurate and helpful answers. Instead of relying on a single prompt, it creates a system that gathers all relevant details from past conversations, user data, documents, and even external tools, and organizes them so that the AI can see the full picture.
Think of it like talking to a friend. If your friend only hears half the story, their advice might be off. However, if they are aware of the full background, including what has already happened and what you truly need, they can provide far better guidance. Context engineering works the same way for AI: it’s not just about supplying information, but also deciding what matters, how to present it, and when to use it. Done correctly, it allows the AI to handle complex queries, recall key details, and respond in a way that makes sense.
Simple Example in Python: This example illustrates how context engineering filters out only the relevant information from a larger knowledge base, enabling the AI to provide accurate and focused answers.
documents = [
"FitJoy Fitness is a home workout app.",
"It includes gamification features like points and streaks.",
"The app offers abs, chest, and leg workout plans."
]
# Retrieve only relevant context
def retrieve_context(query, docs):
return [doc for doc in docs if any(word.lower() in doc.lower() for word in query.split())]
# Simple AI simulator using retrieved context
def simple_ai(query, docs):
context = retrieve_context(query, docs)
if not context:
return "Sorry, I don't have enough information."
return f"Based on what I know: {' '.join(context)}"
# Example usage
query = "Tell me about gamification in FitJoy."
print("Q:", query)
print("A:", simple_ai(query, documents))Output

AI doesn’t just rely on a single piece of information it works with multiple types of data that together form its full context. This includes:
System instructions: These are the rules and guidelines that define how the AI should behave. They set the boundaries and tone for the AI’s responses.
Conversation history and user preferences: The AI remembers past interactions and any preferences you’ve indicated so it can provide more personalized and coherent answers.
Information from documents or databases: The AI often needs to pull in facts, knowledge, or insights stored elsewhere to answer questions accurately.
Available tools and their definitions: If the AI can utilize external tools (such as calculators, APIs, or search engines), it must be aware of what each tool does and when to use it.
Structured outputs and schemas: Some tasks require responses in a specific format, such as JSON or tables, so the AI needs to maintain this structure in mind.
Real-time data and API responses: For tasks that require current information, the AI may need to access live data feeds or external APIs to obtain up-to-the-minute data.
The primary challenge is the limitations of the context window. AI models can only process a certain amount of information at once. To maintain coherent conversations over time, the AI must prioritize the most relevant information to ensure continuity. This often involves building retrieval mechanisms that fetch the right data at the right moment, so the AI always has access to the essential context without being overwhelmed or distracted by unnecessary details.
This also involves creating memory systems that track both short-term conversation flow and long-term user preferences, while removing outdated or irrelevant information to make space for current needs.
The real power of context engineering emerges when all these different types of context work together. For example, when an AI assistant can recall previous conversations, check your calendar, and adapt to your communication style simultaneously, interactions stop feeling repetitive and start feeling genuinely intelligent, almost like you’re talking to a system that actually remembers you.
Why is context engineering important?
When agentic systems fail, it’s almost always because the underlying LLM made a mistake. At a fundamental level, LLM failures happen for two reasons:
- The model itself is imperfect.
- The model wasn’t given the right context.
As LLMs become more capable, the second reason becomes increasingly common. Models need the right information, presented in the right way, to perform well. Failures usually occur because:
- Missing context: Models can’t infer what they haven’t been told. If the relevant information isn’t included, the output will be flawed.
- Poorly structured context: How information is presented matters. Even the best model can struggle if the context is disorganized or unclear.
This is why context engineering is crucial. By carefully curating and structuring the information fed into a model, we can significantly reduce errors and unlock the model’s full potential.
Context Engineering vs. Prompt Engineering
Prompt engineering and context engineering are related, but they’re not the same. Prompt engineering is the process of providing an AI with specific instructions for a task, such as instructing ChatGPT or any other AI tool to “write a professional email.” It’s about getting the AI to do that one thing right. Context engineering is different. It’s about setting up a system so the AI has all the information it needs to respond intelligently over time. For example, a customer service bot that remembers previous tickets, checks user accounts, and keeps track of conversations uses context engineering. In short, prompt engineering handles one-off tasks, while context engineering helps the AI think ahead, remember things, and respond more like a human would.
| Feature | Prompt Engineering | Context Engineering |
|---|---|---|
| Purpose | Give the AI instructions for a single task | Set up a system so the AI has all relevant information for multiple steps or interactions |
| Example | “Write a Professional email” | A customer service bot that remembers previous tickets, checks user accounts, and tracks conversations. |
| Scope | One-off, single requests | Continuous,multi-step, or ongoing interactions. |
| Focus | Crafting the right prompt | Managing context, memory, and relevant information |
| Benefits | AI performs that immediate task correctly | AI responds intelligently, consistently, and more human-like over time. |
Context Engineering vs. RAG
Retrieval-augmented generation (RAG) combines a search step with a large language model, enabling relevant passages from an external knowledge source to be fetched and inserted into the prompt just before generation. This enables the model to provide answers based on up-to-date information, rather than relying solely on its static training data. First introduced in a 2020 paper, RAG has become standard practice at companies like Microsoft, Google, and Nvidia, as it helps ground responses and significantly reduces hallucinations.
| Aspect | Context Engineering | RAG (Retrieval-Augmented Generation) |
|---|---|---|
| Purpose | Structure and manage the information flow to the LLM to improve performance and relevance | Fetch external, authoritative information to provide up-to-date answers |
| Focus | Managing agent state, memory, and context across multiple steps or sessions | Integrating external knowledge dynamically into the prompt before generation |
| Scope | Can include short-term and long-term memory, summarization, and context isolation | Typically focused on retrieval from documents, databases, or other knowledge stores |
| Use Case | Ensuring the LLM has the right context for multi-step workflows, tools, or user-specific interactions | Answering fact-based questions accurately, reducing hallucinations. |
| Implementation | Techniques like state objects, sandboxes, context trimming, and summarization nodes. | Search + retrieval, embedding-based lookups, prompt injections |
| Example | Agent remembers user’s past workouts to plan today’s routine | LLM answers “who won the 2024 Nobel prize in physics” by retrieving the latest articles. |
Context Engineering with LangSmith / LangGraph
To apply these ideas effectively, start with two foundational steps. First, make sure you can examine your data and monitor token usage across your agent. This insight helps you determine where context engineering efforts will have the most impact. LangSmith is ideal for agent tracing and observability, providing a clear way to achieve this. Second, have a straightforward method to test whether your context engineering improves or hinders agent performance. LangSmith also supports agent evaluation, allowing you to measure the effects of any context engineering changes.
In this example, we demonstrate context engineering with a Python agent using LangGraph and LangSmith. The goal is to help the agent provide more accurate responses by controlling the amount of conversation history it considers.
- The user inputs are stored in a conversation history.
- Only the last few messages are provided to the agent, which is the context engineering step.
- LangSmith is used to trace and evaluate the agent’s responses, so you can measure whether your context adjustments improve performance.
This shows how context engineering can make your AI agent smarter and more efficient in handling conversations.
from langchain.agents import initialize_agent, Tool
from langchain.chat_models import ChatOpenAI
from langsmith import Client
# Initialize LangSmith client (for tracing & evaluation)
client = Client(api_key="YOUR_LANGSMITH_API_KEY")
# Example tool
tools = [
Tool(
name="GetCustomerInfo",
func=lambda name: f"Customer info for {name}: Premium Member",
description="Returns basic customer information"
)
]
# Initialize agent with context management
llm = ChatOpenAI(temperature=0)
agent = initialize_agent(tools, llm, agent_type="zero-shot-react-description", verbose=True)
# Example conversation
conversation_history = []
def run_agent(user_input):
# Add user input to conversation history
conversation_history.append({"role": "user", "content": user_input})
# Provide last 3 messages as context
context = conversation_history[-3:]
# Generate agent response
response = agent.run(input=user_input, context=context)
# Add agent response to history
conversation_history.append({"role": "agent", "content": response})
# Trace & evaluate in LangSmith
client.track_agent_response(agent_name="CustomerSupportAgent", input=user_input, output=response)
return response
# Test
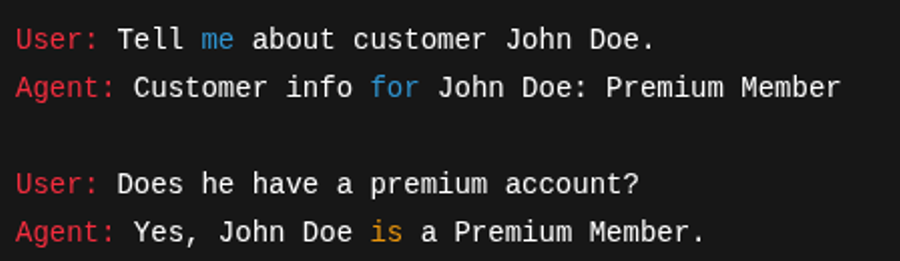
print(run_agent("Tell me about customer John Doe."))
print(run_agent("Does he have a premium account?"))
Expected Output:
When you run the example, the agent will respond to your user inputs based on the last few messages in the conversation history. LangSmith will also log each response for evaluation.
Example console output:
Write context
LangGraph is designed with both short-term (thread-scoped) and long-term memory. Short-term memory uses checkpointing to preserve the agent’s state across all steps. This functions like a “scratchpad,” allowing you to write information to the state and retrieve it at any point during the agent’s execution.
LangGraph’s long-term memory enables you to persist context across multiple sessions with your agent. It is highly flexible, allowing you to store small sets of files (such as a user profile or rules) or larger collections of memories. Additionally, LangMem provides a wide range of useful abstractions to support effective memory management in LangGraph.
Select Context
Within each node (step) of a LangGraph agent, you can access the agent’s state, giving you precise control over the context presented to the LLM at every step.
Additionally, LangGraph’s long-term memory is available within each node and supports multiple retrieval methods, such as fetching files or performing embedding-based lookups from a memory collection. For a comprehensive overview of long-term memory, consider the Deep Learning AI course. To see memory applied to a specific agent, explore the Ambient Agents course, which demonstrates how to use LangGraph memory in a long-running agent capable of managing your email and learning from your feedback.
Compressing context
Since LangGraph is a low-level orchestration framework, you organize your agent as a set of nodes, define the logic within each node, and pass a state object between them. This structure provides multiple ways to compress context.
A common method is to use a message list as the agent state and periodically summarize or trim it with built-in utilities. You can also add logic to post-process tool calls or different phases of the agent. For example, summarization nodes can be added at specific points, or summarization logic can be included within a tool-calling node to compress the output of specific tool calls.
Isolating Context
LangGraph is built around a state object, allowing you to define a state schema and access the state at each step of the agent. For instance, you can store context from tool calls in specific fields within the state, keeping it separate from the LLM until it is needed. Beyond the state, LangGraph supports sandboxes for context isolation. For example, see this repo demonstrating a LangGraph agent using an E2B sandbox for tool calls, and this video showing sandboxing with Pyodide, where state can be persisted. LangGraph also provides extensive support for building multi-agent architectures through libraries such as Supervisor and Swarm. You can find additional videos for more details on using multi-agent setups with LangGraph.
Context Engineering in Practice
Context engineering involves applying theory to real-world AI applications that require working with complex, interconnected information. For example, a customer service bot might need to access past support tickets, check account status, and reference product documentation—all while keeping a friendly and helpful conversation tone. This is exactly where traditional prompting falls short, and context engineering becomes essential.
RAG Systems
Context engineering arguably began with retrieval-augmented generation (RAG) systems. RAG was one of the first techniques that allowed LLMs to access information beyond their original training data.
RAG systems utilize advanced context engineering methods to effectively organize and present information. They break documents into meaningful chunks, rank content by relevance, and fit the most important details within the model’s token limits.
Before RAG, if you wanted an AI to answer questions about your company’s internal documents, you would have to retrain or fine-tune the entire model. RAG changed this by enabling systems to search for documents, identify relevant sections, and include them in the AI’s context window alongside the user’s question.
As a result, LLMs could now analyze multiple documents and sources to answer complex question tasks that would normally require a human to read through hundreds of pages.
Example: The following program demonstrates a simple RAG system in Python. It retrieves relevant information from documents and answers user questions based on that content.
# Example: Simple RAG-like system in Python
documents = [
"FitJoy Fitness helps users build muscle and gain weight with home workouts.",
"RAG systems let AI access external information without retraining the model.",
"Python is widely used in AI, data science, and automation projects."
]
chunks = []
for doc in documents:
chunks.extend(doc.split("."))
chunks = [chunk.strip() for chunk in chunks if chunk.strip()]
from collections import Counter
all_words = []
for chunk in chunks:
all_words.extend(chunk.lower().split())
word_freq = Counter(all_words)
def score_chunk(chunk, question):
chunk_words = chunk.lower().split()
question_words = question.lower().split()
score = 0
for word in chunk_words:
if word in question_words:
score += 1 / (word_freq[word] ** 0.5)
return score
def retrieve_top_chunks(question, chunks, top_k=2):
scored = [(score_chunk(chunk, question), chunk) for chunk in chunks]
scored.sort(reverse=True)
return [chunk for score, chunk in scored[:top_k]]
def answer_question(question):
top_chunks = retrieve_top_chunks(question, chunks)
return " ".join(top_chunks)
print("This program simulates a simple RAG system.")
print("It retrieves the most relevant information from documents and answers your question.\n")
question = input("Ask a question: ")
answer = answer_question(question)
print("\nAnswer:", answer)
Output

AI agents
RAG systems allowed access to external information, but AI agents take this a step further by dynamically and responsively generating context. Unlike RAG, which simply retrieves static documents, agents can leverage external tools during a conversation.
The AI decides which tool is most likely to address a given problem. For example, an agent can initiate a chat, recognize the need for up-to-date stock information, invoke a financial API, and then process the newly retrieved data.
The falling cost of LLM tokens has made multi-agent systems more feasible. Instead of trying to fit all the information into a single model’s context window, you can now use specialized agents to handle different parts of a problem and let them share information with each other through protocols like A2A or MCP.
Here’s a simple Python example that demonstrates how AI agents work internally. It shows how the agent processes a user’s input and decides what to return as the output.
# Simple AI agent in plain Python
def double_number(x):
return x * 2
def agent(prompt):
words = prompt.split()
for word in words:
if word.isdigit():
return double_number(int(word))
return "I don't know how to respond."
# Ask the agent
print(agent("Double the number 15."))
Output

AI Coding assistants
AI coding assistants such as Cursor or Windsurf are among the most advanced examples of context engineering in action. They don’t just look at single files; they understand your entire project, including module dependencies, coding patterns, and how different parts of your code interact.
For example, if you ask a coding assistant to refactor a function, it needs to know where that function is used, what data types it handles, and how any changes might affect other files or modules. Similarly, if you ask it to add a new feature, the assistant has to consider your project structure, recent edits, coding style, and the frameworks you’re using to make accurate suggestions.
Context engineering is what makes this possible. By keeping track of relationships across multiple files or even repositories, a good assistant can provide more informed recommendations that perfectly fit your project. The more you use it, the better it gets at learning your codebase, patterns, and preferences over time.
Other examples include:
- Documentation assistants who update API docs by understanding the connections between functions, classes, and modules.
- Bug detection tools that can trace errors across multiple files and suggest fixes based on how your code interacts with each other.
- Design assistants for front-end projects that adjust UI components while maintaining consistency with your overall layout and style.
With context engineering, AI tools transition from providing generic suggestions to acting almost like a human collaborator who knows your project inside and out.
Context Failures and Techniques to Mitigate Them
After reading the article, you might think that context engineering isn’t really necessary or won’t be in the future as the context windows of cutting-edge models keep getting larger. After all, if the context window is big enough, it seems like you could just throw everything, tools, documents, instructions, into a prompt and let the model handle the rest.
However, Drew Breunig’s article highlights four surprising ways things can still go wrong, even with models that support 1 million token context windows. In this section, I’ll briefly summarize the problems Breunig points out and the context engineering strategies that can help solve them. I highly recommend reading his full article for a deeper understanding of the challenges involved.
Context Poisoning
Context poisoning occurs when a hallucination or error is introduced into an AI system’s context and then repeatedly used in subsequent outputs. DeepMind highlighted this problem in their Gemini 2.5 technical report while developing a Pokémon-playing agent. If the agent occasionally hallucinated about the game state, that incorrect information would contaminate its goals context, causing it to pursue impossible objectives or follow strategies that could never succeed.
This issue is particularly critical in agent workflows that accumulate information over time. Once the context is poisoned, it becomes extremely difficult to correct, as the model continues to treat the false information as accurate.
The most effective mitigation is context validation and quarantine. Before adding information to long-term memory, different types of context can be isolated in separate threads for verification. Context quarantine, the first stage of this process, involves creating new threads to prevent potentially poisoned information from affecting future interactions.
Context Distraction
Context distraction occurs when an AI’s context becomes so large that the model starts focusing more on its past interactions than on the knowledge it learned during training. A notable example is the Gemini Pokémon-playing agent: once its context reached 100,000 tokens, it began repeating old moves instead of generating new strategies.
A Databricks study found that model accuracy in LLaMA 3.1 405B started to decline at around 32,000 tokens, with smaller models reaching their limits much earlier. This suggests that models can make errors well before their context windows are fully populated, raising questions about the effectiveness of extremely large context windows for complex reasoning tasks.
The recommended solution is context summarization. Instead of letting the context grow indefinitely, the model’s history is condensed into concise summaries that capture essential facts and remove redundant information. This approach enables the model, as it approaches its distraction threshold, to recap the conversation so far and continue with a “clean slate,” ensuring responses remain coherent, relevant, and focused.
Context Confusion
Context confusion happens when you add extra information to the AI’s context that isn’t relevant to the task, but the model still tries to use it, often producing incorrect or unhelpful responses. For example, in the Berkeley Function-Calling Leaderboard, models performed worse when given more than one tool, and sometimes even attempted to use a tool unrelated to the task at hand.
Smaller models and the addition of too many tools can exacerbate this problem. In a recent experiment, a quantized Llama 3.1 8B model failed on the GeoEngine benchmark when given all 46 tools, despite the context window being far below its 16k token limit. However, when the number of tools was limited to 19, the model performed well.
The solution is to manage the tool loadout effectively, and RAG (Retrieval-Augmented Generation) techniques are particularly useful in this context. A study by Tiantian Gan and Qiyao Sun showed that storing tool descriptions in a vector database and retrieving only the most relevant ones significantly improves performance. Their experiments found that limiting the selection to fewer than 30 tools tripled the accuracy of tool selection and shortened the prompt length, making AI responses faster and more accurate.
Context Clash
Context clash happens when new information or tools are added to an AI’s context that conflict with what the model already knows. A study by Microsoft and Salesforce demonstrated this by “sharding” benchmark prompts, splitting the information across multiple conversational turns rather than providing it all at once. The results were striking: average performance dropped by 39%, with OpenAI’s O3 model falling from 98.1 to 64.1.
This problem occurs because early, incomplete information in the context can lead the model to make mistakes. When new, conflicting data is added later, the AI may continue to rely on its earlier, incorrect attempts, which then influence its final answers.
The best ways to handle context clash are context pruning and context offloading. Context pruning involves removing outdated or conflicting information as new details become available. Context offloading, such as Anthropic’s “think” tool, provides the model with a separate workspace to process information without cluttering its main context. This “scratchpad” approach has been shown to improve performance by up to 54% on specialized agent benchmarks, preventing contradictions from disrupting reasoning.
Conclusion
Context engineering is essentially about advancing AI—from models that provide one-off answers to systems that can engage in meaningful conversations and handle complex tasks over time. The techniques we examined, such as RAG, summarization, memory systems, and smarter tool management, are already proving their value in real-world applications that support millions of users.
The main lesson here is simple: if you want to build anything beyond a basic text generator, you’ll need context engineering. And the best part? You don’t have to build the most advanced system right away. Start with something small, such as adding retrieval to your app, and then gradually layer in memory, context pruning, and tool orchestration as your needs grow.
This shift from prompt engineering to context engineering is what turns AI from something that just “responds” into something that actually understands and adapts.
FAQs
What is context engineering in AI?
The art of designing systems that instruct an AI model on the information it needs to access before formulating a response is called context engineering. It utilizes conversation history, documents, tools, and real-time data, rather than relying solely on a single prompt, to ensure the AI responds more accurately.
How is context engineering different from prompt engineering?
Prompt engineering is concerned with instruction on a single task (such as writing an email). Context engineering, however, ensures that in numerous interactions, the AI recalls user preferences, finds the appropriate information, and works with tools, thus becoming much more powerful in complex apps.
Why do we need context engineering if context windows are getting bigger?
Larger context windows are useful, although they do not solve all the problems. Unless the surrounding is handled well, models may still become confused, distracted, or even commit the same mistakes. Context Engineering is a system of delivering to the AI only the information that is relevant and valuable.
Is context engineering difficult to platform?
Not necessarily. You can start small, such as adding a simple RAG system to retrieve documents, and scale up over time. As your application grows, you can layer in memory, summarization, and tool orchestration.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
