
Context Engineering: The Hidden Blueprint Behind Reliable AI Agents in 2025
Amit Eyal Govrin

TL;DR
- Context engineering is the practice of structuring everything an LLM needs prompts, memory, tools, data to make intelligent, autonomous decisions reliably.
- It moves beyond prompt engineering, focusing on designing the full environment in which an agent operates, not just the questions it receives.
- The 12-Factor Agent framework adapts classic software engineering principles (like control flow, stateless design, and modularity) to LLM-powered systems.
- By treating tool calls as structured outputs (e.g., JSON) and separating reasoning (LLM) from execution (code), systems become more scalable and testable.
- Owning your context window and control loop allows agents to recover from errors, collaborate with humans, and act predictably.
- Smaller, focused agents improve clarity, resilience, and maintainability making them suitable for real-world production use cases.
Even a year ago, the term “context engineering” didn’t even exist. And today, it is one of the most popular terms across the AI landscape. In mid-2025, CEOs and AI engineers became excited about context engineering. Many started tweeting about it, many began making videos, and many were explaining why it’s much better and more important than “prompt engineering.” The ideas behind context engineering have existed well before the term was coined. However, the term itself gives us a clear and helpful way to think about the biggest challenges in building smart and reliable AI agents.
On June 19, the CEO of Shopify, Tobias Lütke (X handle @tobi), posted on X about this, and after this, it started getting a lot of attention. On the X post, he mentioned:
‘I really like the term “context engineering” over prompt engineering.
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.’
After this X post, context engineering has now become a buzzword everywhere. But it’s important to understand what it actually means and how you can use it to build reliable agents in 2025. Let’s get into the breakdown.
Context Engineering: From Prompting to Systemic Design
“Prompt engineering” was a trendy term for a long time after the revolution sparked by ChatGPT at the end of 2022. The arrival of ChatGPT was indeed a seminal moment. It changed everything. It helped bring AI into the mainstream tech world.
But practices in the AI landscape were bound to evolve, and they did. Prompt engineering is quite outdated now. Context engineering is the new norm.
What is Context Engineering?
You need to arrange a birthday party, and you've hired a world-class chef. Now, if you simply tell the chef, “Cook a meal for our birthday party,” they will definitely prepare something delicious, but it may or may not be what the guests were expecting. As a result, you’ll have to keep going back and telling the chef what to change, again and again.
Now, consider a second scenario: You provide the chef with all the relevant details about the birthday party and the guests:
- The number of vegetarian and non-vegetarian guests
- The fact that the guest of honor loves spicy Mexican food, especially dishes like chiles rellenos and queso fresco
- A recipe they’ve enjoyed before
- The list of available ingredients in the kitchen (e.g., corn, beans, avocados, jalapeños)
- A reminder not to use nuts (some guests have allergies)
With all this information, the chef can now prepare exactly the right dish. Tailored, safe, and delicious.

Similarly, the LLM is like the chef. If you only provide it with a prompt, no matter how well-structured, it may or may not produce the correct output. You need to prompt it again and again until you get considerable output. To get the best results, you need to fill the LLM’s context window with optimal information about the task at hand. This ensures the model fully understands the goal and delivers responses that are accurate, relevant, and high-quality every time.
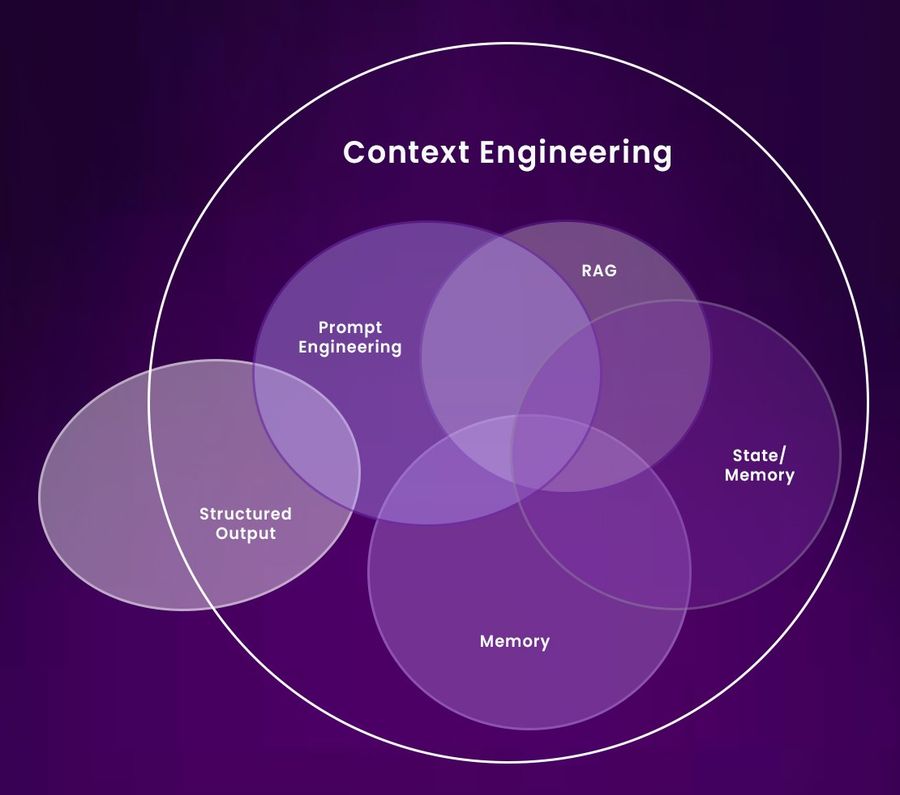
So, what exactly is Context Engineering? Context Engineering is the "delicate art and science" (according to Andrej Karpathy, director of AI at Tesla) of precisely filling a Large Language Model's (LLM) context window with optimal information for a given task. This goes beyond simple prompts, strategically including task details, examples, and relevant data (like RAG) to ensure the LLM has the necessary context for superior performance, balancing cost and output quality.
For a better understanding, here is a table mentioning the differences between prompt engineering.
Context Engineering vs Prompt Engineering
| Dimension | Prompt Engineering | Context Engineering |
|---|---|---|
| Definition | Crafting effective inputs (prompts) to get accurate responses from an LLM | Designing the full information environment around the LLM to enable autonomous reasoning |
| Focus | How to ask the AI a question effectively | How to set up everything the AI needs to answer questions or take actions independently |
| Model Type | Applies to general LLMs like GPT, Claude, Bard, etc. | Mainly relevant for LLM-based AI agents and multi-agent systems |
| Control Flow | Prompt defines what to do next | Control logic is owned by the system; LLM gives suggestions within a defined framework |
| Goal | Maximise the quality of a single output | Enable reliable, autonomous, and context-aware agent behaviour |
| Analogy | Like giving precise instructions to a new intern | Like onboarding and equipping the intern with all company tools and policies |
Why do we need Context Engineering?
Building agents that are not just demos but truly production-ready is a challenging task. It’s not just about complex coding. What it is more about is the quality of the context in which the agent is trained. Many can quote different frameworks that promise out-of-the-box solutions but those AI-powered products marketed as "agents" fall short of actual agentic behaviour. Instead, they often rely heavily on deterministic code, with large language model (LLM) calls strategically placed to create the illusion of intelligence. That's where context engineering comes to play.
Say you are a regional sales director and you send a message to an internal AI assistant:
Can you put together a Q3 update deck for Acme Corp?
Without strong context, the agent responds generically:
Sure. What would you like me to include in the presentation?
Although polite and functional, this response offers little value. The assistant is unaware of past interactions, current account status, or internal expectations. It is forcing the user to manually guide it through every detail.
With strong context, the agent behaves differently. Before responding, the system enriches the model’s prompt with relevant information, like:
- CRM data: contract value, renewal date, growth trends.
- Support logs: ongoing issues Acme flagged last quarter.
- Internal notes from the last account review.
- Email summaries: key discussions between Acme stakeholders and the team.
- Company presentation templates.
- Access to tools for creating and sharing slide decks.
Now, the agent replies something like this:
I’ve gathered Acme’s Q3 sales metrics, current renewal pipeline, and support tickets from the past 90 days. Drafted a presentation in your usual format, with performance highlights and proposed action items. It's available in your Drive under “Acme_Q3_Update”. Let me know if you'd like to review or adjust it.
The difference isn't in a smarter model. It's in the design. The assistant isn’t trying to guess. It’s been given the right context to fulfil the task effectively. This is what context engineering enables: systems that deliver real value by operating with awareness of the task, history, tools, and business goals.
Problem with the “loop until you solve it” pattern and how the 12 factors solve it
Agents work in a repeating cycle (loop) made up of three steps:
- The LLM decides what to do next, usually by outputting a structured JSON command (often called “tool calling”).
- Deterministic code takes the LLM’s request and executes the “tool call.”
- The result is added back to the context for the LLM to consider in the next step.
This loop continues until the LLM decides the task is complete. Something like the image below.
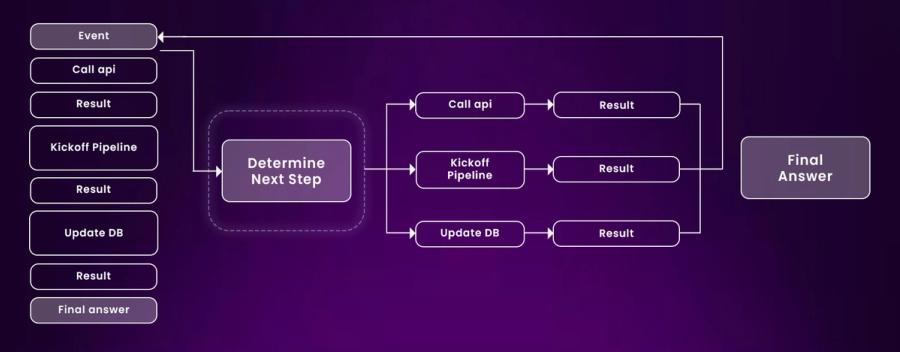
One major flaw with the “loop until you solve it” approach is that agents often lose track of what they’re doing when the context window becomes too large. As the conversation or task history grows, they can end up repeating the same failed strategy again and again, stuck in a loop. This single issue is significant enough to undermine the entire method.
Rather than relying on traditional "prompt-tool-repeat" loops, the most effective AI agents are grounded in software engineering fundamentals. They are crafted deliberately with clear control flows, ownership of context, and deep attention to the quality of token inputs. There are 12 factors that provide a proper roadmap for building reliable, maintainable, and high-quality LLM-based software systems through context engineering. Below, we explore each of the 12 core principles of context engineering in detail.
The 12 Factors: Engineering Reliable LLM Applications
The 12 Factor App Legacy
The original 12 Factor App, created by Heroku in 2011, laid out best practices for building reliable cloud apps. Now, those ideas are being reimagined for AI. The 12-Factor Agent framework takes the same disciplined approach—this time for large language models. While LLMs are powerful, using them effectively requires more than good prompts. It’s about designing smart systems around the model. This approach focuses on practical, real-world techniques that make AI agents more dependable, scalable, and easier to maintain. Think of it as a modern engineering guide for anyone building serious AI-powered applications. Here are the 12 core factors.
- Factor 1: Natural Language to Tool Calls: Leverage the LLM's core strength to transform human language into structured, executable commands.
- Factor 2: Own Your Prompts: Meticulously craft and control every token in your prompts for optimal and reliable LLM output.
- Factor 3: Own Your Context Window: Curate and optimize the information fed into the LLM's context for precision and efficiency.
- Factor 4: Tools Are Just Structured Outputs: Understand that LLM "tool use" is simply the model producing structured data for deterministic code execution.
- Factor 5: Unify Execution State and Business State: Clearly manage both the internal operational status and the real-world data of your agent.
- Factor 6: Launch/Pause/Resume with Simple APIs: Design agents to be controlled and managed like standard software services via clear interfaces.
- Factor 7: Contact Humans with Tool Calls: Enable agents to explicitly signal when human intervention or clarification is required.
- Factor 8: Own Your Control Flow: Define the agent's workflow using traditional programming logic, with the LLM guiding steps within this structure.
- Factor 9: Compact Errors into Context Window: Summarize and intelligently convey errors to the LLM to facilitate robust self-correction.
- Factor 10: Small, Focused Agents: Break down complex problems into modular, specialized micro-agents for improved reliability and management.
- Factor 11: Trigger from Anywhere, Meet Users Where They Are: Allow agents to be accessed and interacted with across diverse communication platforms.
- Factor 12: Make Your Agent a Stateless Reducer: Design agents to process state externally, ensuring they remain stateless and scalable.
To provide a comprehensive overview of how to build reliable agents, we are going to mix up the factors, so they will not be in order in the next section. We'll bundle the factors based on their logical interdependencies and the natural flow of designing and implementing an LLM-powered application.

I. Foundations: Structuring Core LLM Interactions
To build a reliable AI agent, first, we need to fix the foundations. For that, we need to structure the core LLM interactions. This category establishes a robust and predictable base for LLM agent operations, focusing on fundamental interactions with the LLM itself.
Factor 1: Natural Language to Tool Calls
The framework posits that the fundamental capability of LLMs lies in their ability to convert natural language into structured data, specifically JSON.
For example, a user might say:
"Schedule a meeting with the design team for next Monday at 10 AM to review the new mockups. Make it a video call."
This natural language request could be translated into a structured object for a calendar API (like Google Calendar API) like this:
{
"function": {
"name": "create_calendar_event",
"parameters": {
"title": "Design Mockup Review",
"attendees": [
"design_team@example.com"
],
"start_time": "2025-07-14T10:00:00",
"end_time": "2025-07-14T11:00:00",
"location": "Video Conference",
"description": "Meeting to review the new mockups."
}
}
}
This principle emphasises the effective translation of natural language inputs into structured tool calls that the LLM-powered software can execute. This perspective re-frames the LLM's role from a general conversationalist to a highly specialised parser and function caller, treating it as a sophisticated "compiler" that produces structured, actionable data.
Factor 2: Own Your Prompts
The reliability of an LLM’s output heavily depends on the quality of its input prompts. While tools can generate effective prompts, achieving high reliability often requires developers to manually craft and fine-tune prompts. In LLMs, output quality is determined by input tokens. Owning your prompts means experimenting with different structures to find the most effective configuration, ensuring consistent and accurate agent behaviour.
But why should you own your prompts?
- When you write your own prompts, you're in full control. You’re not relying on hidden abstractions; you know exactly what your agent is being told to do. This makes your system more transparent and easier to debug.
- It also gives you the ability to test and evaluate your prompts just like any other part of your codebase. If something isn’t working well in the real world, you can tweak the prompt and see immediate results.
- Owning your prompts also opens up opportunities for advanced techniques, like playing with user/assistant roles in clever ways or using models in non-standard modes (like OpenAI’s old completions API).
- Ultimately, prompts are the key bridge between your app’s logic and the model itself. If you want to build agents that are reliable enough for real-world use, you need the freedom to try everything, and that starts with taking ownership of the prompt.
Factor 4: Tools as structured outputs
When people think about tools in LLM agents, they often imagine them as real-time actions, APIs, scripts, or services that the model somehow runs. But in reality, the LLM doesn’t actually do anything. It just outputs structured data, usually JSON, that tells your system what to do. Think of it like the LLM writing an instruction note, and your deterministic code executing it.
This separation of responsibilities is powerful: the model reasons and decides what should happen, while your code handles the execution. That’s why it’s critical to treat tool calls as structured outputs, not side effects.
Even complex “next steps” might span multiple actions or require human input. When you view tool use this way, and combine it with Factor 8: Own Your Control Flow, you unlock deep flexibility. Your system stays in charge, deciding how to act, when to retry, or escalate. The LLM just provides the plan.
What Is a Tool in This Context?
In this structured-output paradigm, a "tool" refers to any deterministic operation that your system can perform in response to a model’s output. The LLM doesn’t actually call or invoke the tool. Instead, it generates a structured data object that represents a request for a specific action. Your system then parses that request and performs the action accordingly.
For example, if your application supports creating support tickets and searching existing issues, the model might output a structured request to "create a ticket" along with the necessary information. Your code is responsible for recognising the intent and executing the appropriate operation.
Why This Structured Output Pattern Works
This structured output pattern, where the LLM emits clearly defined instructions and your system executes them, offers three key advantages:
- Separation of Concerns: The LLM is responsible for deciding what should happen. Your system is responsible for determining how to make it happen. This separation keeps model logic clean, debuggable, and testable.
- Predictability: By validating the structure of the model’s outputs using schemas or constraints, you can ensure the system only processes well-formed, expected instructions. This guards against errors and untrusted input.
II. State & Control: Mastering Agent Behavior and Lifecycle
We’ve covered the foundational principles for structuring how LLMs interact, transforming language into tool calls, crafting reliable prompts, and treating tools as structured outputs. Now, it’s time to shift our focus to what happens next: managing the agent’s behaviour over time.
Reliable AI agents aren't built by one-shot inference. They operate in ongoing workflows, often spanning multiple steps, retries, or even human interventions. This makes the internal state, context history, and execution control just as important as the model’s reasoning itself.
This section focuses on managing the internal state, context, and operational lifecycle of LLM agents, ensuring predictability, scalability, and debuggability.
Factor 3: Own Your Context Window: The Fundamentals of Context Engineering
A large language model (LLM) is a stateless function. It generates outputs solely based on the input it receives at each invocation, with no memory of past interactions unless explicitly included. For example, if you ask, “What’s the weather like today?” followed by “And tomorrow?”, the model won’t understand the reference to “tomorrow” unless the first question is also present in the input: “What’s the weather like today? And what about tomorrow?” The LLM doesn't retain memory across turns on its own.
To build reliable, production-grade AI agents, developers must take full control over what information gets passed into the model. Context engineering focuses on precisely shaping that input, curating prompts, history, tool outputs, and relevant data to give the model everything it needs to perform accurately and autonomously.
At any point during an agent's execution, the task is effectively:
“Here’s everything that’s happened so far. What’s the next step?”
By owning your context window, you gain precision, efficiency, and adaptability in how you represent this “everything so far.”
What Constitutes Context?
Owning your context means consciously structuring the full input to your LLM. This includes:
1. The prompt template and operational instructions
Example: "You are a helpful assistant that explains medical terms in simple language. Always respond in under 100 words." (Sets role, tone, and constraints.)
2. External documents or search results (e.g., via RAG)
Example: "According to the Mayo Clinic, symptoms of heat stroke include high body temperature, altered mental state, and nausea." (Provides factual grounding from retrieved documents.)
3. Prior tool calls, states, or intermediate outputs
4. Conversation history or event memory
Example: User: Can you send the Q2 report?
Assistant: Sure! Do you want the Excel version or PDF?
User: PDF, please.
(Gives the LLM continuity for ongoing conversations.)
5. Error traces, metadata, and human inputs
Example: "Error: 'client_id' field missing in request payload. Retry count: 2. Manual override by user: true." (Helps the LLM understand failures and human interventions.)
6. Expected output formats and structured data hints
Example: "Please respond with a JSON object including 'title', 'summary', and 'next_steps' fields." (Guides the model to produce predictable, parsable output.)
Factor 5: Unifying Execution and Business State for Simpler AI Agents
Think of your AI agent like a version-controlled codebase. In traditional systems, execution state (like current step, retries, or wait flags) lives in separate runtime controllers, while business state (like user messages and tool outputs) is stored elsewhere. This is like tracking your code changes in one system and your commit history in another. Unnecessary overhead.
Instead, unify them. Treat the context window, the full thread of events, as your single source of truth, like a Git history log. Each event (tool call, user input, LLM output) becomes a commit. This way, the entire state is inspectable, serialisable, forkable, and resumable. No need for extra metadata layers. You simply replay the thread to reconstruct everything the agent knows and has done.
By reducing separation, you gain clarity, resilience, and maintainability, just as a good version control system does for code.
Factor 6: Launch, Pause, and Resume Agents with Simple APIs
AI agents should behave like any other program. Easy to start, pause, and resume. A clean API makes it easy to launch an agent from a UI, app, or automation pipeline without complex orchestration. When agents hit long-running tasks or need input, they should pause gracefully. Once external input (like a webhook or user action) arrives, the agent should resume exactly where it left off.
This design keeps agents flexible and modular. Combined with unified state management and clear control flow, it makes agents easier to scale, test, and recover.
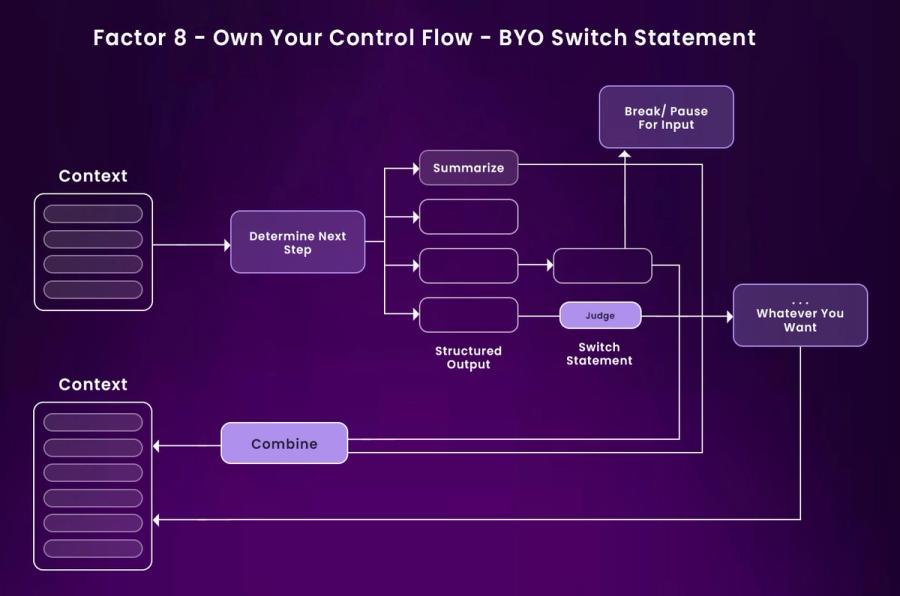
Factor 8: Own Your Control Flow
A well-designed agent needs more than just great prompts. It needs a control loop that you own. That means deciding when to continue, when to pause, and when to involve a human or external process. Instead of treating the agent as a black box, treat it like any other service in your architecture.
By owning the control flow, you can implement logic for:
- Pausing until human clarification arrives
- Triggering a long-running job and resuming after completion
- Skipping ahead on trivial operations
- Intercepting and approving risky actions
Here's a working example of a basic control loop:
python
def handle_next_step(thread: Thread):
while True:
next_step = await determine_next_step(thread_to_prompt(thread))
# Inlined for clarity – refactor to method or use exceptions as needed
if next_step.intent == 'request_clarification':
thread.events.append({
type: 'request_clarification',
data: next_step,
})
await send_message_to_human(next_step)
await db.save_thread(thread)
# Async step – break the loop, await external input
break
elif next_step.intent == 'fetch_open_issues':
thread.events.append({
type: 'fetch_open_issues',
data: next_step,
})
issues = await linear_client.issues()
thread.events.append({
type: 'fetch_open_issues_result',
data: issues,
})
# Sync step – continue immediately
continue
elif next_step.intent == 'create_issue':
thread.events.append({
type: 'create_issue',
data: next_step,
})
await request_human_approval(next_step)
await db.save_thread(thread)
# Async step – break and wait for approval
This control loop gives your agent the flexibility to handle simple queries instantly and pause responsibly on complex or sensitive ones. It also enables better monitoring, safe recovery, and more predictable behaviour in production.
Owning control flow is foundational to building agents that are robust, trustworthy, and production-ready, especially when paired with unified state and resumability.
Factor 12: Make Your Agent a Stateless Reducer
Treat your agents as stateless functions (or "transducers" with multiple steps) that receive an input state and produce a new output state. The agent itself doesn't hold state; rather, the state is managed externally (e.g., in a database) and passed into the LLM as part of the context for each turn. This promotes scalability, robustness, and easier debugging.
III. Human-Agent Collaboration: Designing for Seamless Interaction
After establishing the core mechanics of agent operation, context control, state management, and execution logic, the next essential layer is human collaboration. Even the most advanced agents will occasionally need human input for clarification, approval, or decision-making. This section explores how agents can explicitly engage humans through structured mechanisms, making collaboration clear, traceable, and reliable.
Factor 7: Contact Humans with Tool Calls
Sometimes agents need help from humans. Especially when making high-stakes decisions. Instead of relying on vague language, you can define tool calls specifically for human input. This makes the agent's intent clear and the response structured, like asking, “Should we deploy now?” with a yes/no format.
By treating human input as a tool, agents can pause, wait for a response, and resume later, tying directly into Factor 6 (Pause/Resume) and Factor 8 (Control Flow). It also complements Factor 3 (Context Window) by capturing interactions in a readable, traceable format.
This approach makes agents more reliable, collaborative, and suited for real-world scenarios where humans and AI work side by side through durable, event-driven workflows.
Factor 11: Trigger from Anywhere, Meet Users Where They Are
Triggering agents from anywhere, be it Slack, email, SMS, or an automated system, makes them truly useful in real-world workflows. Instead of only responding to direct chat prompts, agents can be launched by events, schedules, or alerts. This design aligns with Factor 6 (Pause/Resume) and Factor 7 (Contact Humans), enabling seamless coordination.
Think of agents as digital coworkers who can monitor tasks, wait patiently, and then reach out when needed. Whether it’s a cron job, a service outage, or a human request, agents should be able to start, stop, or continue operations flexibly.
This approach unlocks high-stakes use cases, like pushing to production or emailing clients. Because humans can step in quickly, review decisions, and keep the loop auditable and controlled.
IV. Production Excellence: Building Robust and Scalable Systems
Till now, we’ve covered both autonomous logic and human interaction in place. Now, the final step is ensuring your agent architecture can scale and endure in production. This section focuses on principles that improve system reliability, maintainability, and performance under real-world conditions. From modular design to error resilience, these practices ensure your agents move beyond prototypes into long-term operational success.
Factor 10: Small, Focused Agents (Micro Agents)
Instead of building massive agents that try to do everything, create smaller ones that each handle a specific task well. This “micro-agent” pattern mirrors good software design: focused, testable components that are easy to reason about. Long workflows increase context size, making LLMs lose track or behave inconsistently. By limiting agents to 3–10 steps, you improve clarity, performance, and reliability.
As seen in real-world deployments, like triggering deployment pipelines from Slack, most production-ready agents run short loops and pass control back to deterministic code. This hybrid pattern gives you the best of both: flexible reasoning and reliable execution. Even as LLMs get more powerful, this approach will remain valuable for debugging, scaling, and maintaining clarity across your system.
Smaller agents also let you compose bigger workflows using stateless, controlled units, supporting pause/resume, tool calls, and human input. It’s not just scalable. It’s smart engineering.
Factor 9: Compact Errors into Context Window
One of the simplest yet most powerful ways to make agents more resilient is by letting them “self-heal.” When a tool call fails, say, due to an API error or a bad parameter, the agent shouldn’t crash or get stuck. Instead, capture that error and feed it back into the context window. LLMs are surprisingly good at reading error messages and adjusting their next move.
This technique works even if you ignore every other factor. Just append the error to your thread and let the model try again. However, don’t let it loop endlessly. Use error counters, three strikes, maybe, then either reset, reframe, or escalate to a human.
This plays well with Factor 3 (Own Your Context) and Factor 8 (Own Your Control Flow): rephrase or summarise errors, prune the history, and stay in control. And, most importantly, it works best when paired with small, focused agents—so your context stays tight and meaningful.
Conclusion
Context engineering isn’t just a new buzzword—it’s the foundation of reliable AI systems in 2025. It bridges LLM capability with disciplined engineering, helping agents move from flashy demos to real-world utility. By owning context, control, and structure, developers gain clarity, control, and confidence in their AI agents. It’s not just clever prompting—it’s software architecture for intelligence.
FAQs
What is an engineering context?
In LLM-based systems, engineering context refers to the carefully constructed input the model receives, including prompts, past interactions, tool outputs, and any relevant state. It's the engineered environment in which the model operates to generate meaningful outputs.
What is the meaning of contextual engineering?
Contextual engineering means designing and structuring the inputs (context window) that surround an AI agent, enabling it to reason accurately and act reliably. It includes prompt design, memory construction, tool outputs, and the entire event history that informs the model.
What is the role of context in prompt engineering?
Context shapes how an LLM interprets a prompt. While a prompt is the direct instruction, the surrounding context provides the background, constraints, memory, and tooling references that let the model understand and perform the task effectively.
What does "engineering" mean in the context of the talk?
In this context, "engineering" refers to applying software design principles—like modularity, control flow, structured state, and separation of concerns—to build LLM-based agents. It’s not about crafting prompts alone, but about engineering the system that enables intelligent behaviour.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
