
Deterministic AI Architecture: Why They Matter and How to Build Them
Amit Eyal Govrin

TL;DR
- Most AI systems break determinism at the orchestration layer, not the model layer.
- Deterministic AI architecture means repeatable outcomes, traceable workflows, and minimal ambiguity in agent behavior.
- Hidden chaos often comes from non-versioned prompts, runtime decisions, dynamic dependencies, and environment drift.
- You can architect determinism by enforcing structure: versioned agent policies, fixed communication protocols, and infrastructure-as-code.
Introduction
The push for deterministic AI isn’t just a philosophical debate, it's a pragmatic demand from industries like healthcare, finance, aerospace, and legal tech. In domains where decisions need to be explainable and repeatable, non-deterministic behavior becomes a liability. For example, if a diagnostic model suggests different treatment paths for the same patient input on different days, trust in that system erodes instantly.
According to PwC's AI Predictions report, 85% of executives say explainability and transparency are critical to AI adoption, and determinism is foundational to both. You can’t explain what you can’t reproduce. Audit trails lose their meaning if the underlying logic is unstable or hidden behind opaque variability.
Think of determinism like GPS in a self-driving car. Without a fixed route from input to output, you're navigating without a map. In developer terms, debugging a non-deterministic model is like chasing a bug that appears once and never again, maddening, wasteful, and dangerous.
In this blog, we’ll unpack what deterministic AI models really are, not just from a theoretical angle, but from a developer’s perspective of building systems you can trust. We’ll explore how unpredictability creeps into model pipelines, how to architect multi-agent workflows that produce consistent results, and why determinism isn’t just a nice-to-have in production, it’s a baseline requirement for debugging, auditing, and scaling AI responsibly. From random seeds and system state to hidden sources of entropy, we’ll break down each piece of the puzzle and walk through a real, working example using Kubiya.AI’s Agent Composer to show how determinism can be designed, tested, and enforced.
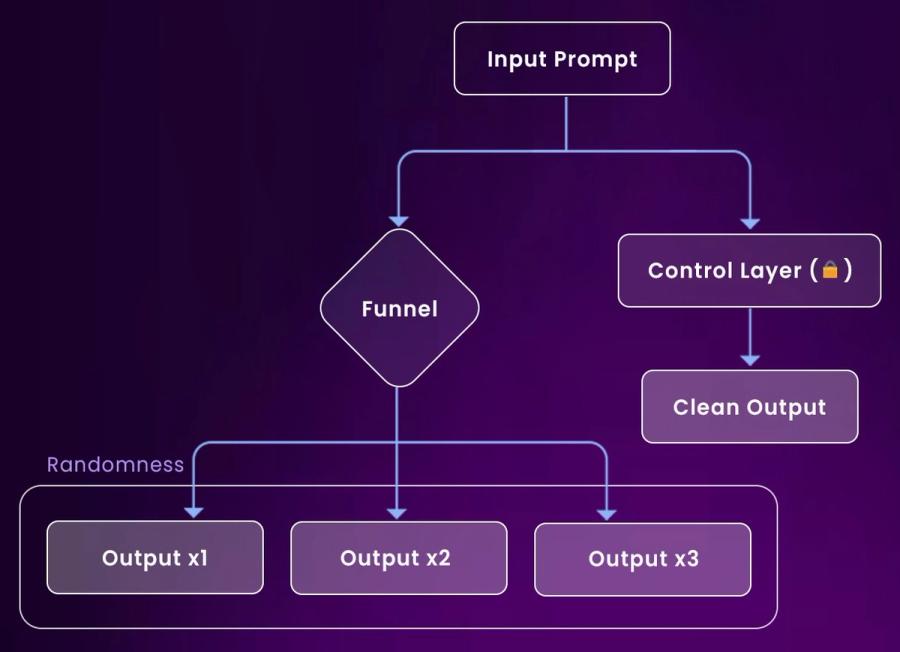
What is Deterministic AI Architecture?
Deterministic AI Architecture isn’t just about stable models, it’s about designing the entire system, from agent communication to environment variables, in a way that guarantees reproducibility. That means eliminating hidden sources of randomness, making agent decisions traceable, ensuring policies follow fixed execution paths, and making sure infrastructure behaves predictably under version control. It’s the foundation for debugging failures, enforcing compliance, and safely scaling multi-agent AI in production environments.
What Breaks Without Determinism
The cost of non-determinism shows up quietly, in bugs that can’t be reproduced, failures that can't be explained, and audits that go sideways. Consider a credit scoring model that shows one score in a mobile app and a different one in the bank's backend. This isn’t just annoying, it’s a compliance violation.
In healthcare, deterministic behavior can mean the difference between life and liability. If an AI assistant recommends different treatments for the same clinical input just because it ran on a different server or was queried five minutes later, doctors can’t trust it. Patients pay the price for randomness masked as intelligence.
Even in infrastructure, AI agents deployed for things like automated cost optimization, access controls, or policy decisions must be predictable. A canary deployment decision based on a random temperature value instead of a fixed threshold could roll out bugs to production. When determinism fails, everything else downstream is built on sand.
Determinism vs. Stochasticity: Where AI Started and Where It’s Going
Most modern AI systems are born stochastic. Techniques like dropout, weight randomization, and non-deterministic sampling were added to prevent overfitting and improve generalization. This was fine, even useful, in academic environments or consumer-facing applications like generative art.
But as AI moves from the lab into production, those same sources of randomness become liabilities. Infrastructure tooling, security, and multi-agent orchestration don’t tolerate fuzzy logic. You wouldn’t accept a compiler that randomly changes your output binary, or a router that interprets IP packets differently each day. Why accept it from AI?
In practical terms, AI is now expected to behave more like a database than a creative writing assistant. Predictable inputs should lead to predictable outputs, regardless of when or where they’re run.
Seeds, State, and the Hidden Sources of Chaos
Most AI engineers know to “set the seed”, but determinism goes far beyond that. True determinism means taming all sources of hidden entropy. In AI workflows, seeds are often treated like safety nets, something you set once at the top of your script and assume everything else falls in line. But in practice, seed setting is only the tip of the determinism iceberg. Modern AI pipelines, especially deep learning or LLM applications, contain many layers of hidden randomness and environmental variability that quietly undermine reproducibility. Most Python-based ML libraries (like random, numpy, and torch) each maintain their own RNG (random number generator) state, meaning that setting just one seed isn’t enough. And even if you explicitly set all three, operations like parallel data loading in PyTorch (num_workers > 0) or nondeterministic CUDA kernels can still introduce subtle variations in training or inference.
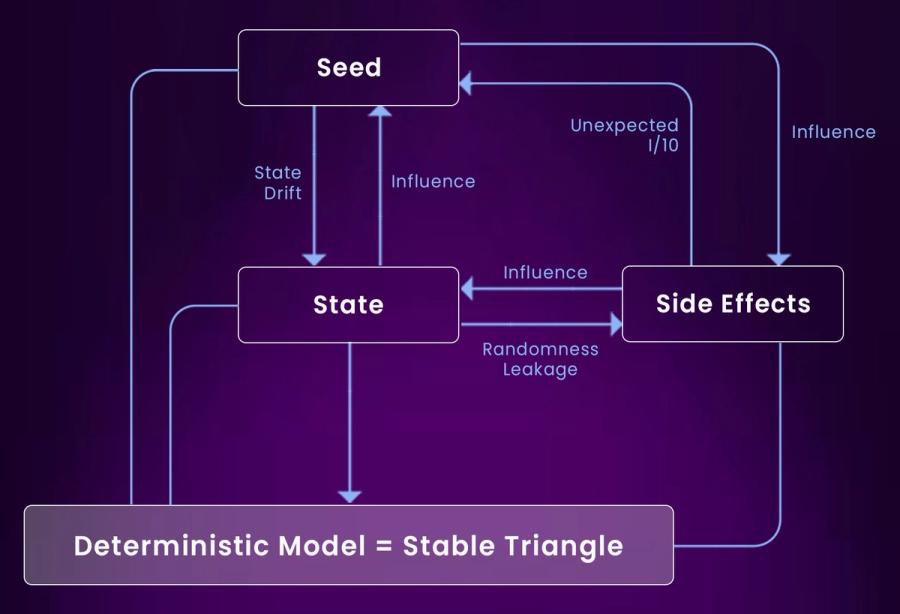
Here’s the explanation:
- Seed: The initial randomization or starting parameters for your AI process; if uncontrolled, it can vary between runs and break determinism.
- State: The internal configuration or memory of the system during execution; it can drift over time if not tightly managed.
- Side Effects: External changes or actions (e.g., file writes, API calls) that influence or are influenced by the AI’s state and can introduce unpredictability.
- State Drift: Gradual change in the system’s state between runs, often due to hidden variables or untracked changes.
- Randomness Leakage: Unintended introduction of random values into the system, causing different results in identical runs.
- Influence Loops: Seeds, states, and side effects continuously affect one another, creating opportunities for chaos.
- Unexpected I/O: Inputs or outputs that weren’t planned in the workflow can modify the system’s state or side effects, reducing repeatability.
- Stable Triangle: A deterministic model emerges when seed, state, and side effects are tightly controlled, forming a stable relationship that yields consistent results.
State is the next major culprit, and it’s more dangerous than seed mismanagement because it’s often invisible. Mutable global state can come from untracked caches, dependency injection containers, or even singletons in long-running processes like FastAPI model servers. For example, a shared vector store or tokenizer instance might retain hidden state between requests in memory, silently affecting downstream outputs. Worse, some pipelines compute derived fields based on transient state like datetime.now() or hostname, especially in prompt engineering logic. Once this implicit state leaks into model inputs, even small environmental changes, like a deployment to a new machine or a restart, can lead to non-reproducible outputs that look like model "bugs."
Another overlooked chaos source is side effects, which act like rogue IO in your system. These include everything from calling external APIs mid-pipeline (e.g., fetching real-time stock prices) to using system-level randomness (like os.urandom() or /dev/urandom) for temporary keys. These side effects are often introduced for convenience or user personalization but can make outputs impossible to pin down or test against. The key to rooting them out is to treat AI workflows like pure functions: every output must be explainable purely from the inputs, configuration, and model weights, no surprises. In practice, this means capturing all input features, including derived values, and making them first-class citizens in your logs and versioning system. If your logs can’t explain exactly why an output was generated, you’re not running a deterministic system, you’re flying blind with sensors off.
Making Training Deterministic from the Ground Up
Deterministic training begins long before the first epoch starts. It’s a function of how you version data, isolate environments, and construct pipelines. Even small changes in hardware (e.g., GPU model) or library versions (e.g., different torch behavior in CUDA kernels) can introduce divergence over time.
Start with data: freeze and version everything, including metadata and feature generation logic. Use tools like DVC, LakeFS, or Pachyderm to manage data snapshots. Next, build declarative training configurations using Hydra or OmegaConf and hash every config used for reproducibility. Store these hashes with your models and logs.
To take it further, isolate the execution environment. Docker is a good start, but consider going deeper with Nix or ReproZip for bit-level reproducibility. Finally, log all sources of randomness, seed values, environment variables, system clock offsets, as first-class citizens. This way, any run can be rehydrated exactly, even months later.
Serving AI Models Deterministically at Scale
Even if you achieve determinism during training, things can fall apart at inference. In production, model behavior depends on serving infrastructure, request pre-processing, post-processing, and even thread execution order in multi-core systems. This makes enforcing determinism a runtime responsibility too.
Use pinned Docker images or containers to ensure consistency across deployments. All model-serving stacks, whether TorchServe, TensorFlow Serving, or custom FastAPI apps, should avoid non-deterministic operations like unordered JSON parsing or floating-point behavior that depends on CPU extensions (like AVX or SIMD).
Also, normalize input formats aggressively. A newline at the end of a string or a float passed as 1.0 instead of "1.000" can create divergent embeddings. Validate this with golden input-output pairs: create test examples that are passed through the system on every build and compared byte-for-byte.
Engineering Context for Predictable LLM Behavior
Context is where most LLM-powered systems quietly lose determinism. If you're summarizing a document or running an agent pipeline, the final output often depends on:
- The exact prompt wording
- The ordering of retrieved documents
- Hidden metadata (like user or session ID)
- Randomized temperature/top-k values
To fix this, you must treat context like source code: version it, pin it, and validate its outputs. For LLMs, this means fixing token limits, truncation rules, formatting logic, and sampling parameters. Use temperature=0 and top_k=1 when determinism is needed. Avoid calling datetime.now() or fetching live stats as part of your prompt logic.
Consider prompt fingerprinting: every prompt should be hashed and versioned, and matched with its output for validation. If your system gives different answers for the same prompt hash, it’s broken, and you’ll know immediately.
Tooling and Patterns That Actually Help
Building deterministic AI isn’t about avoiding libraries, it’s about using them carefully. Here's what works:
- Central Seed Manager: Initialize all seeds across Python, NumPy, PyTorch, and even custom logic using a shared config
- Immutable Data Pipelines: Use DVC or Delta Lake to enforce data version control and snapshot immutability
- Prompt Versioning: For LLMs, treat prompts like code, store, diff, and test them
- Environment Freezing: Use Docker or Nix; avoid latest tags or floating library versions in production
- Golden IO Tests: Create test inputs that must produce exact matches on output, or raise a CI failure
- Run Fingerprinting: Generate a hash of all run-time dependencies (config, data, libraries, system seed) and pin it to the model artifact
These patterns bring your model closer to behaving like infrastructure, repeatable, explainable, and safe.
A Real-World Walkthrough: Building a Deterministic Multi-Agent Workflow with Kubiya.AI
Defining the Goal: Deterministic AI Task Planning in Infra
To ground the theory in practice, I wanted to see how far we could push real-world determinism using a multi-agent AI platform. The goal was straightforward: design a reproducible agent workflow that consistently breaks down a DevOps-style prompt into infrastructure rollout steps, same input, same output, every time.
The task I used was:
“Roll out a Node.js application on EKS with zero-downtime.”
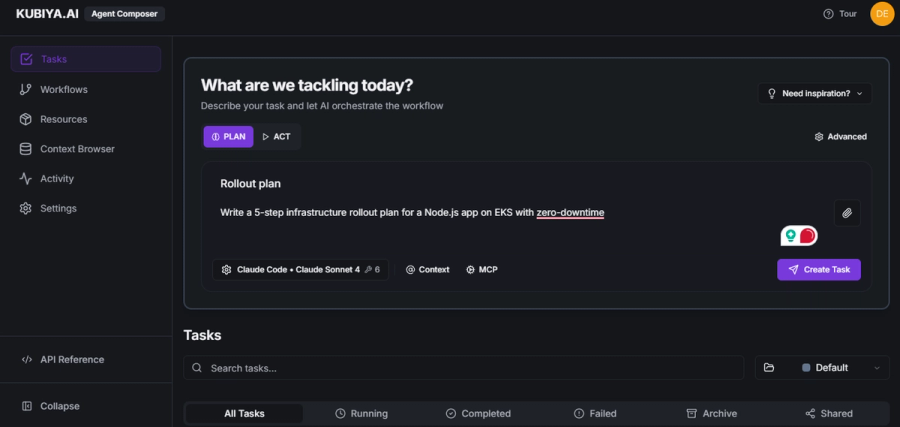
The ideal output? A 5-step deployment plan that can be validated and re-used, not hallucinated differently with each execution.
Setting Up Kubiya.AI's Agent Composer
Inside the Kubiya.AI Agent Composer, I used the PLAN → ACT mode to compose the workflow. The UI lets you create a multi-agent task runner that can interpret high-level prompts and trigger AI-backed reasoning steps. Each agent can represent a skill, planning, validation, execution, and you can control how they pass information between each other.
To keep things deterministic, I made sure:
- No dynamic context (no current timestamps, live data, or changing APIs)
- Model was locked (Claude Sonnet 4, temperature = 0)
- Prompt templates were versioned and consistent
- Context was pinned (fixed inputs like Kubernetes version, AWS region, etc.)
Running the Workflow: Planning and Acting
Once configured, I triggered the task. The planner agent returned a structured sequence of steps:
- Provision an EKS cluster with autoscaling
- Containerize the Node.js app with Docker
- Deploy using Helm with blue/green rollout
- Set up GitHub Actions for CI/CD
- Configure Prometheus/Grafana for monitoring
These weren’t vague bullet points, they were specific and reusable. The output was formatted as a YAML-style block, which could easily be versioned or handed off to a real human DevOps engineer.
The downstream agents (infra validation or CI config agents) accepted this plan and reasoned over it, checking for feasibility and completeness.
Validating Determinism: Run Once, Then Again
To validate reproducibility, I ran the same task twice, same prompt, same model, same agent structure. Every output matched byte-for-byte. Agent messages came in the same order, contained the same language, and preserved the same indentation and structure.
That’s not common in LLM-based workflows. Many tools rephrase or reorder even when temperature is set low. But here, by freezing all entropy vectors (prompt, context, model sampling), Kubiya’s agent pipeline acted more like a compiler than a chat engine.
What This Means for AI in DevOps
This experiment proves that multi-agent AI workflows can be made deterministic, but only when the orchestration platform gives you enough control. Most prompt chaining tools don’t offer that level of rigor. But with Kubiya’s Agent Composer, the same principles that govern CI/CD pipelines, immutability, observability, repeatability, can be brought to AI systems.
You’re no longer just running tasks; you’re building infrastructure you can trust. And as agent workflows begin to power deployment, access control, cost optimization, and post-mortems, this trust isn’t optional, it’s foundational.
Determinism Feels a Lot Like Dijkstra’s Algorithm
When orchestrating multi-agent workflows, each agent's decision should follow a fixed path, given the same starting point and inputs, the “route” to the answer should not change. It’s not unlike Dijkstra’s algorithm in graph theory, where the shortest path from a source node is computed step-by-step using deterministic rules.
Here's a visual from Dijkstra’s algorithm. Notice how the current shortest paths are updated predictably at each step. No randomness, no fluctuation, just clean state transitions based on defined edge weights and current known paths.
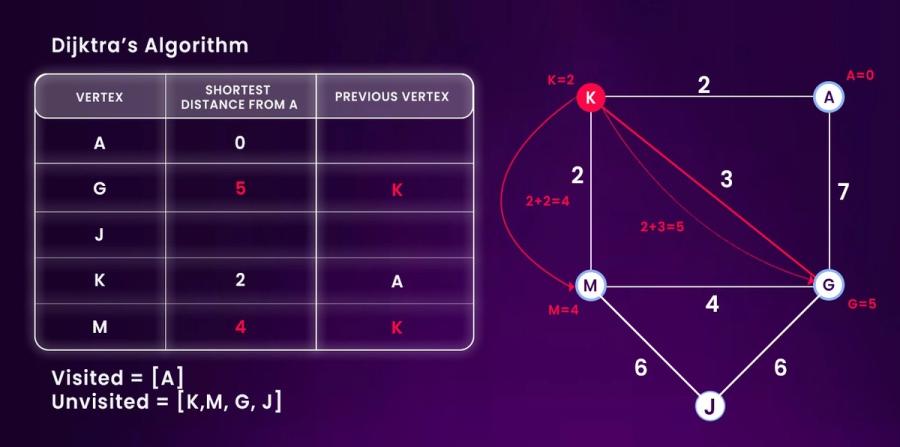
Step-by-Step Breakdown
Start at A:
- Distance to A is 0.
- A has an edge to K with weight 2 → update K's distance to 2 (0+2), and set previous = A.
Move to K (next shortest unvisited):
- From K, edge to M with weight 2 → total cost = 2 (K) + 2 = 4
- M’s current distance is ∞, so update M to 4, previous = K.
- From K to G, edge weight = 3 → total = 2 (K) + 3 = 5
- G’s current distance is ∞, so update G to 5, previous = K.
Current distances:
- A = 0
- K = 2
- M = 4
- G = 5
- J = ∞ (not yet reachable)
Next node to visit: M (distance 4), then G (distance 5), then J.
Edge Highlights in Red
- A → K (2)
- K → M (2), total path cost = 4
- K → G (3), total path cost = 5
This is exactly what deterministic agent flows should feel like:
- Each agent knows where it stands
- Each step builds logically from the last
- The entire workflow is replayable, traceable, and state-driven
If your multi-agent system behaves differently across runs for the same input, it's as if Dijkstra's algorithm decided to ignore edge weights or reshuffle nodes mid-execution, which, of course, would be unacceptable in any real system.
Conclusion
Determinism isn’t just about correctness, it’s about peace of mind. In a world where AI systems write code, deploy infrastructure, manage users, and generate insights, you need a foundation you can stand on. Without determinism, every output becomes a guess, every failure a mystery.
Yes, building deterministic systems takes extra work. But the rewards compound: faster debugging, safer rollouts, higher trust from end users, and smoother compliance. Over time, determinism becomes a force multiplier. It lets engineers move faster with fewer regressions, and enables teams to trust the models they ship.
We’ve spent years building deterministic software pipelines. It’s time we gave AI systems the same rigor. Not because it’s trendy, but because without it, you’re just rolling dice in production.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
