
The Ultimate Enterprise AI Checklist for 2025: What to Evaluate Before You Build
Amit Eyal Govrin

Enterprise AI isn’t just about building smarter bots or integrating LLM APIs into your Slack channels. In 2025, it’s about building systems that can reason, make decisions, and operate with minimal human oversight, while still being safe, governed, and maintainable.
But before you start wiring up a fine-tuned LLaMA model or experimenting with a proprietary DevOps copilot, you need structure. This isn’t the kind of initiative where you jump in with a weekend prototype. You need a framework. This guide provides a practical and technical AI readiness checklist, refined for teams considering platforms like Kubiya, or building their own orchestration systems.
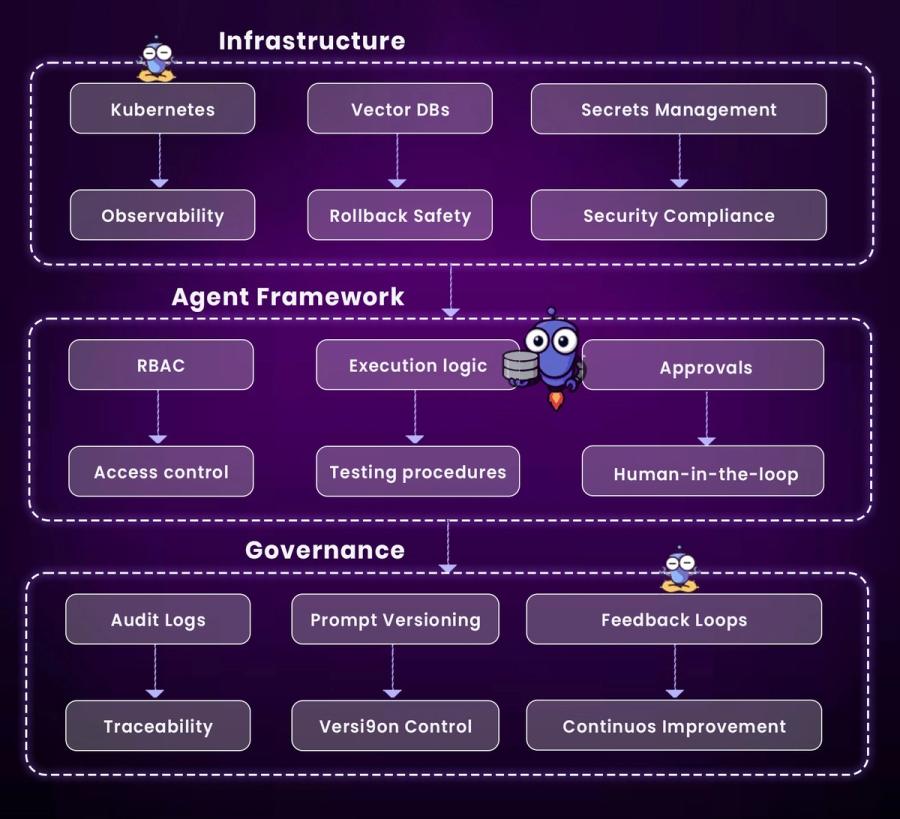
Infrastructure Layer
Ensures the environment is production-ready for agents.
- Kubernetes → Observability: Agents run on K8s with monitoring in place.
- Vector DBs → Rollback Safety: Knowledge is retrievable and agent actions reversible.
- Secrets Management → Security Compliance: Sensitive data is protected and access is policy-bound.
Agent Framework Layer
Defines how agents are orchestrated and interact with users.
- RBAC → Access Control: Agents operate within scoped permissions.
- Execution Logic → Testing Procedures: Logic is validated before being deployed.
- Approvals → Human-in-the-loop: Risky actions require manual confirmation.
Governance Layer
Guarantees accountability, control, and improvement.
- Audit Logs → Traceability: Every action is tracked and reviewable.
- Prompt Versioning → Version Control: Prompts are maintained like source code.
- Feedback Loops → Continuous Improvement: Agents improve based on usage and results.

Enterprise AI Checklist for 2025
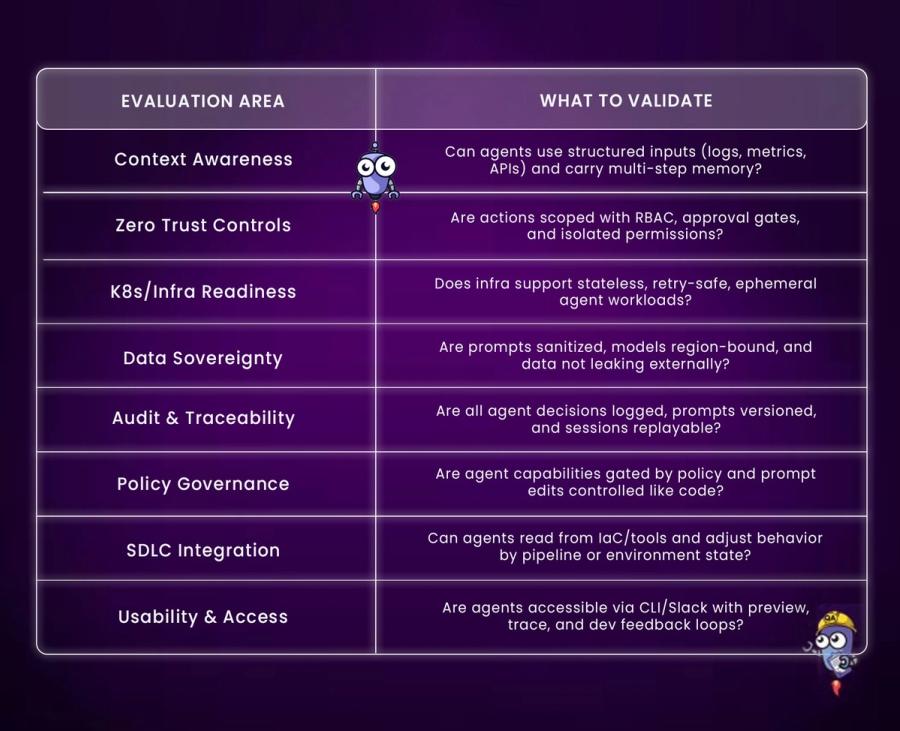
1. Context-Aware Agents
AI agents must move beyond text-only interactions. They should consume structured data, logs, test results, system metrics, and use it as execution context. Without this, your agent is just another chatbot guessing in the dark.
Effective orchestration means agents understand where they’re running, what triggered them, and how to act based on real-time system state. Whether it’s summarizing failing CI jobs or interpreting a Terraform plan, structured context is key to making reliable decisions.
Checklist:
- Can agents pull structured data (logs, metrics, APIs)?
- Is multi-step memory preserved during execution?
- Do agents understand the environment or infra context?
- Can they differentiate staging vs prod automatically?
Example: An agent reviewing CI failures should not just say “your job failed,” but summarize logs, point out the failed test case, and suggest changes only for affected components.
2. Zero Trust Execution
AI should not have blanket access to your infra. Every action must be gated by RBAC, scoped to the minimum privilege needed, and optionally passed through human approval if risk is involved.
The Zero Trust model treats agents like any other external actor. They shouldn’t be able to delete a namespace unless a role allows it, or restart a production service without an approval path. If you wouldn’t hand a junior engineer unrestricted kube access, don’t give it to an agent either.
Checklist:
- Does each agent/task have scoped permissions?
- Is RBAC tied to identity providers (Okta, SSO)?
- Are destructive actions gated by approval?
- Can agents run in sandbox/test environments first?
Example: An agent suggesting a kubectl delete pod should only execute in staging unless an engineer approves escalation to production.
3. Kubernetes-Scale Stateless Execution
Enterprise AI agents must run as ephemeral workloads, stateless, restartable, and isolated. They should integrate cleanly with Kubernetes or your serverless stack, supporting autoscaling, isolation, and resource constraints.
This means no long-lived agent containers holding memory, no manually managed state. Agents should spin up per request, perform their task, write results to a queue or log, and shut down cleanly, just like any modern compute workload.
Checklist:
- Can agents run as K8s Deployments, CronJobs, or serverless functions?
- Are they stateless between invocations?
- Is retry behavior idempotent and safe?
- Are timeouts and resource limits configured?
Example: A rollback agent should run as a Kubernetes Deployment exposed via an internal service or API. It listens for pipeline failures, fetches the last known good release from ArgoCD or Helm, and initiates a rollback after verifying RBAC and approval checks. The agent logs each step and exits cleanly once rollback completes.
4. Data Sovereignty
Data fed to agents, especially prompts and context, must not leave the organization’s control unless explicitly allowed. Many proprietary models send data to third-party endpoints (e.g., OpenAI), which may violate compliance.
You need model hosting options that stay within geographic or logical boundaries. Even for hosted LLMs, prompts should be scrubbed or anonymized before being sent. For highly sensitive environments, prefer self-hosted OSS models like Mistral or LLaMA3.
Checklist:
- Are prompts sanitized before external inference?
- Is model traffic restricted to known regions?
- Do agents support OSS/self-hosted model fallback?
- Can teams disable external API calls per workload?
Example: An agent reading customer metadata should mask PII fields before prompt injection, and use an internal inference endpoint rather than a public API.
5. Auditability
Every decision, action, and input from an AI agent should be logged and replayable. Treat prompts like code: version them, diff changes, and store them alongside CI config or service code.
You should be able to answer: Who triggered this agent? What context was it given? What action did it take, and why? Without this, troubleshooting becomes impossible and accountability disappears.
Checklist:
- Are prompt versions tracked like code commits?
- Is every agent action timestamped and logged?
- Can sessions be replayed for debugging?
- Are audit logs tamper-resistant and queryable?
Example: If an agent incorrectly scaled a service, logs should show what prompt it used, what decision path it followed, and who approved the action.
6. Policy Governance & Enforcement
Just like code goes through CI checks and security policies, agents should pass policy enforcement too. You don’t want a rogue prompt executing Terraform across all regions because someone copied it from ChatGPT.
Governance means you control who can create/edit prompts, which agents are allowed to touch prod, and which workflows require multi-stage approvals. This is where prompt registries, policy-as-code, and signed execution flows become crucial.
Checklist:
- Are prompt changes reviewed and version-controlled?
- Can only specific roles update agents or prompts?
- Are high-risk actions policy-gated (e.g., drift remediation)?
- Are all agent actions logged against policy scopes?
Example: An agent that edits DNS records should only run if the change is reviewed, tagged safe, and approved by on-call SRE.
7. State-Aware Tools (IaC / SDLC)
AI agents should be aware of the delivery state they operate in. That means understanding IaC tools (Terraform, Helm), pipeline states (GitHub Actions, CircleCI), and SDLC checkpoints (code freeze, release windows).
Agents that blindly suggest actions without knowing the infra or delivery state risk causing downtime or conflicts. Context from plan files, deployment manifests, and pipeline outputs should drive their logic.
Checklist:
- Can agents parse Terraform plans or Helm diffs?
- Do they know the pipeline stage they’re in?
- Is environment metadata passed into prompts?
- Can they block actions during freeze or deploy windows?
Example: An agent proposing to apply Terraform in production should first check if it’s outside the code freeze window and validate the plan is safe.
8. UI / Usability
AI won’t be adopted unless it fits inside the tools engineers already use. Whether it's Slack, CLI, VSCode, or GitHub Actions, agents need native interfaces for visibility, execution, and feedback.
Usability also means fast iteration. Developers should be able to test prompts, inspect agent logic, and tweak behavior without needing a full retrain or rebuild.
Checklist:
- Are agents accessible via CLI, Slack, or GitHub comments?
- Can devs test prompts and inspect agent flows?
- Is there a visual debugger or trace view?
- Are errors and logs shown in developer-friendly format?
Example: A Slack-triggered rollback agent should respond with a rollback plan, allow inline approval, and post completion logs to the same channel.
Practical Scenario Walkthroughs
Example 1: CI/CD Failure Assistant
An agent that reads CI logs, detects common patterns like broken environment variables or API rate limits, and suggests or even triggers a re-run after fixing config issues.
Example 2: Secure Slack Assistant for Rollbacks
Triggered via Slack: “Rollback staging to last good build.” The agent checks deployment history, validates staging readiness, and initiates a rollback using ArgoCD, with approval flow and confirmation before applying.
Example 3: Terraform Linter Agent
An agent that reviews your .tf files in a PR, highlights deprecated providers or missing inputs, and can auto-comment on the PR, similar to a GitHub Action, but LLM-powered.
Quick Checklist Recap
Conclusion
AI in 2025 isn’t going to be defined by how many bots you deploy, it’ll be defined by how safely and effectively those bots drive real outcomes. Tools like Kubiya help teams move fast without breaking things, giving you orchestration, observability, and permissioning from day one.
Use this checklist not as a launchpad, but as a pre-flight inspection. Because in AI, a little structure now saves a lot of rework later.
FAQs
1. What exactly is an enterprise AI agent compared to a typical chatbot?
Enterprise AI agents differ from chatbots in that they not only respond to queries but also perform tasks, execute actions, and integrate with internal systems. Rather than just generating text, they can call APIs, run scripts (e.g., rollback a deployment), and orchestrate workflows, while enforcing RBAC, logging every step, and enabling human approvals. This action-oriented capability is at the heart of platforms like Kubiya.
2. What are some common use cases for enterprise AI?
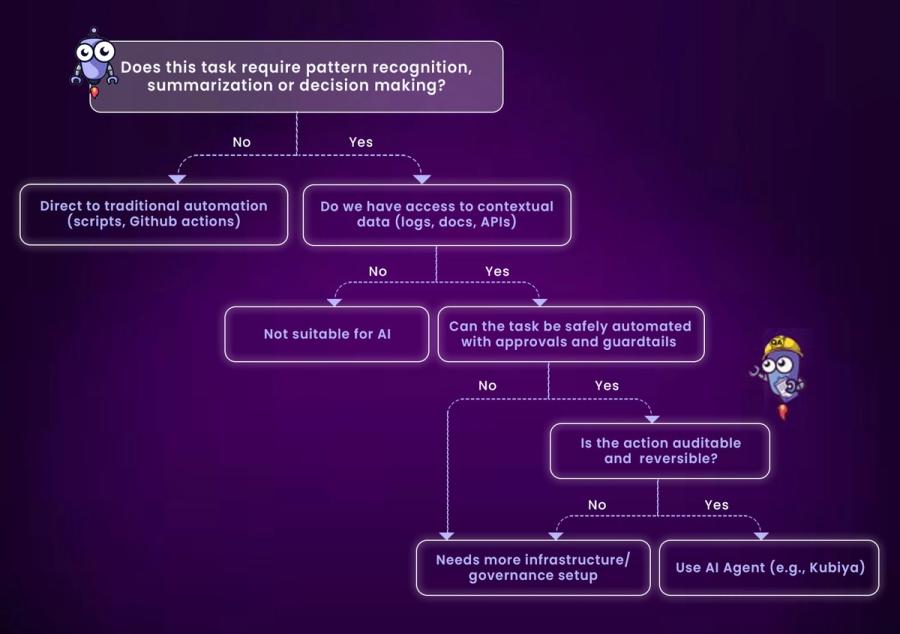
Teams often search for use cases like automated runbook execution, CI/CD failure diagnosis, incident ticket summarization, or Terraform configuration policing. The most effective ones involve pattern recognition, summarization, or autonomous decision-making, such as having an agent read CI logs, detect errors, suggest fixes, and trigger retries with approval. These use cases go beyond simple automation and demonstrate real impact both technically and operationally .
3. How do I evaluate and ensure data privacy with an enterprise AI platform?
Enterprises frequently ask:
- “What data is the model trained on?”
- “Will our data be retained or shared with external vendors?”
You need full transparency on data usage. Ask whether models are open-source or proprietary, and whether any data leaves your perimeter. Self-hosted or on-prem options offer more control, but come with more operational overhead. Platforms like Kubiya support both hosted and self-managed models, and scope sensitive data using RBAC and encrypted stores.
4. What infrastructure and governance components are essential before building enterprise AI?
Successful adoption requires more than just models. You'll want new infrastructure capabilities: scalable GPU/CPU runtime; vector databases for RAG; secure secret and API key management; and full observability across agents. Equally important are governance controls: prompt versioning, audit logs for agent actions, RBAC layers, human-in-the-loop workflows, and rollback paths. These layers ensure trust, compliance, and maintainability in production environments .
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
