
Cloud, On-Prem, or Hybrid? How To Create Enterprise AI Strategy
Amit Eyal Govrin

Enterprise AI is no longer limited to building isolated models, it now spans large-scale training pipelines, low-latency inference systems, and complex orchestration across environments. Choosing the right infrastructure isn’t just a technical decision; it determines scalability, security posture, and cost-efficiency.
In this guide, we break down cloud, on-premises, and hybrid infrastructure models specifically from the perspective of enterprise AI strategy workloads, including the practical tradeoffs and tooling for each approach.
Why AI Breaks Traditional Infrastructure Models
Enterprise AI isn’t just “another app.” It breaks assumptions traditional infrastructure was built on. AI systems aren’t just computer-hungry, they’re bursty, data-heavy, latency-sensitive, and compliance-bound in ways that most backends never are.
1. Burst compute needs: Training a foundation model like LLaMA or fine-tuning a BERT variant isn’t a steady workload, it’s a high-GPU spike that might last a few hours, then drop to zero. Imagine renting an entire stadium for a single concert. Cloud GPUs make that possible, but not always cost-effective.
2. Data gravity and movement: Training data often lives across disparate sources, data lakes, internal SQL systems, or S3 buckets. Moving 10TB+ of data from on-prem to cloud can rack up thousands in egress charges, and may not even be legally permitted in regulated regions. AI workflows follow the data, or pay for it.
3. Inference latency and uptime: If you’re deploying a chatbot, fraud detection model, or search ranking system, even 100ms of added latency can break UX. Running inference 100% in the cloud can introduce unpredictable latency unless you’re regionally pinned or caching smartly.
4. Regulatory constraints: Industries like finance, defense, and healthcare are bound by compliance standards like HIPAA, FedRAMP, or PCI-DSS. For these orgs, “just push it to the cloud” isn’t viable, data residency, audit logging, and runtime isolation are non-negotiable. On-prem or hybrid becomes a requirement, not a preference.
AI systems stress infrastructure like Formula 1 cars stress race tracks, you need a setup built not just for speed, but for burst speed, weight, and regulation. Choosing the wrong surface slows you down or takes you off the track entirely.
How to Create an Enterprise AI Strategy
Building an AI strategy for the enterprise isn't just about choosing models, it's about aligning technical execution with business goals, infrastructure maturity, and compliance boundaries. Here's a practical step-by-step approach:
Step 1: Identify High-Impact, Feasible Use Cases
Start by asking: What problems are we solving with AI, and why now? Focus on use cases that directly impact business KPIs or operational efficiency. Examples include:
- Reducing churn through predictive analytics
- Automating support ticket triaging using classification models
- Generating summaries for long legal documents using LLMs
Avoid use cases that sound impressive but lack measurable impact or production feasibility. Collaborate with business teams to validate real pain points and understand the workflows you’re enhancing or replacing.
Step 2: Evaluate Data Readiness and Accessibility
Even the best model architecture fails without clean, usable data. At this step, assess:
- Where your data lives (cloud buckets, data warehouses, SQL databases, etc.)
- Whether it's labeled, complete, and structured enough for training
- What compliance rules apply (HIPAA, GDPR, internal security controls)
If your data is siloed across teams or hard to access due to privacy concerns, solving those issues must come before model development. Consider investing in data pipelines, versioning tools (like LakeFS or DVC), and labeling workflows that can scale.
Step 3: Choose the Right Infrastructure Model
This is the operational backbone of your AI system. Don’t choose based on trend, choose based on workload, data gravity, latency, and compliance needs.
- Cloud-first: Best for quick experimentation, elastic GPU access, and global deployment
- On-prem: Required for sensitive data, regulated environments, or guaranteed latency
- Hybrid: Allows training in the cloud and inference on-prem or at the edge
For instance, if you’re a hospital, you might train a model in GCP using de-identified datasets, but deploy the final model on-prem for inference, keeping patient data local.
Step 4: Define and Standardize the Model Lifecycle
Think of your model lifecycle the way you think of a CI/CD pipeline for code. Every AI project should follow a repeatable flow:
Ingest data → Preprocess → Train → Evaluate → Register → Deploy → Monitor
Use orchestration tools like Kubeflow Pipelines, Vertex AI, or MLFlow to codify this flow into reproducible components. This lets multiple teams work consistently, reduces human error, and accelerates delivery.
Also, plan for versioning, of both data and models, so that any experiment or deployment can be traced back and reproduced if needed.
Step 5: Operationalize AI with MLOps Pipelines
AI in notebooks is a demo. AI in production needs automation. This step is about bringing DevOps principles to ML:
- Use GitHub Actions, Jenkins, or GitLab CI to trigger training jobs
- Deploy models through ArgoCD or KServe into Kubernetes clusters
- Define infrastructure using Terraform or Pulumi, and store everything in version control
Set up testing gates, rollout strategies, and rollback mechanisms, treat model promotion as you would a backend service deployment.
Step 6: Build in Governance, Security, and Compliance
Don’t wait until a compliance audit to implement governance. Design it in from the start.
- Track model versions and associated datasets
- Record who trained, approved, and deployed each model
- Use RBAC (Role-Based Access Control) to manage permissions
- Monitor for drift, fairness, or performance degradation over time
Especially with GenAI or models touching customer data, you’ll need safeguards to ensure responsible usage. Integrate tools for audit trails and model explainability if required by your industry.
Step 7: Iterate and Scale Across Teams
Once you’ve operationalized your first few models, the strategy shifts from "getting it working" to "scaling it up."
- Create reusable templates and base projects for new use cases
- Offer internal tooling, SDKs, or wrappers for deployment and monitoring
- Standardize your AI/ML development stack to reduce tech sprawl
- Measure not just model accuracy, but cycle time from idea → production
Your goal is to reduce friction at every stage, so that teams don’t reinvent infrastructure or compliance layers every time they build a new model.
Infrastructure Models Explained - And Their AI Tradeoffs
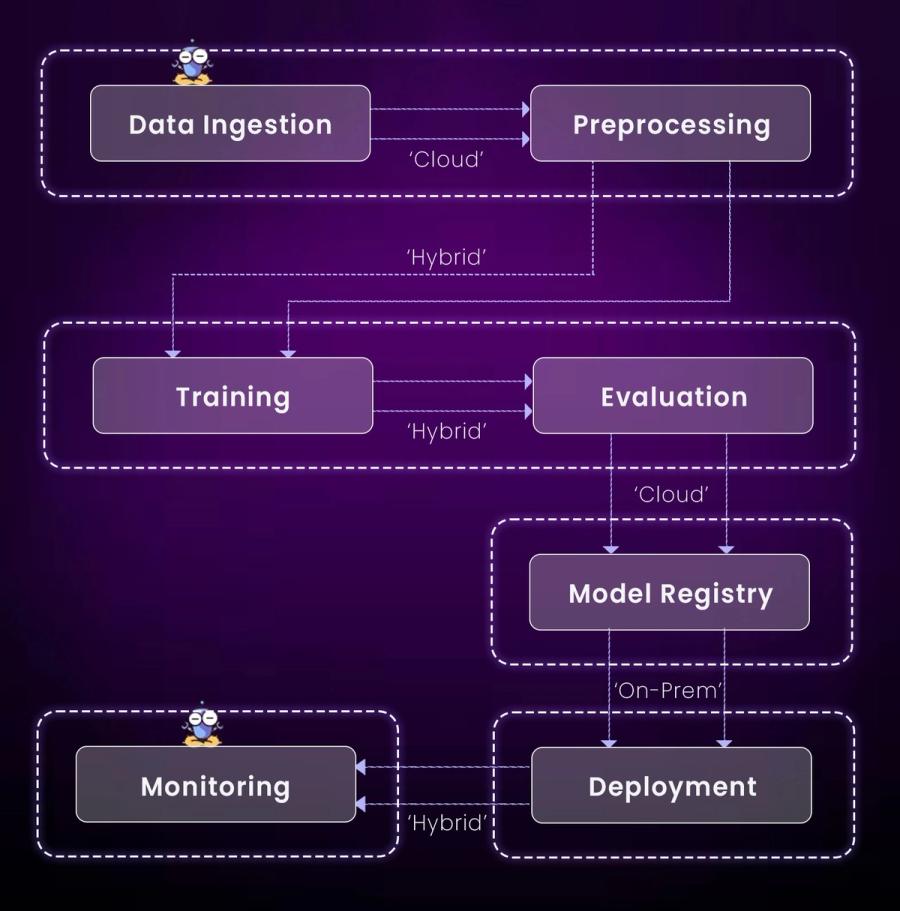
Before choosing where to run your AI workloads, it’s essential to understand the core infrastructure models available. These models define how your compute, data, and orchestration layers are structured, whether fully managed in the cloud, entirely self-hosted, or spread across environments. In enterprise AI, the most common models are Cloud, On-Prem, and Hybrid infrastructure. Each comes with its own strengths, operational tradeoffs, and suitability depending on your use case, team maturity, and compliance needs.
Let’s break each down with a focus on how they impact training, inference, and scaling AI in production.
1. Cloud Infrastructure
Cloud platforms offer elastic compute, managed AI services, and global reach, making them a popular choice for AI experimentation and prototype deployment.
Best For:
- Model experimentation and fine-tuning
- Scaling burst training jobs
- Startups and greenfield projects
Example: Training a BERT Classifier on Vertex AI (Cloud)
Let’s say you’re fine-tuning a BERT model for text classification. You’ve written the following trainer/task.py script:
# trainer/task.py
import os
import transformers
from datasets import load_dataset
from transformers import Trainer, TrainingArguments, BertForSequenceClassification, BertTokenizerFast
def main():
model_name = "bert-base-uncased"
tokenizer = BertTokenizerFast.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
dataset = load_dataset("imdb")
dataset = dataset.map(lambda e: tokenizer(e['text'], truncation=True, padding='max_length'), batched=True)
dataset.set_format(type='torch', columns=['input_ids', 'attention_mask', 'label'])
args = TrainingArguments(
output_dir=os.environ.get("AIP_MODEL_DIR", "./model"),
evaluation_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=2,
save_strategy="epoch",
logging_dir="./logs"
)
trainer = Trainer(
model=model,
args=args,
train_dataset=dataset["train"].shuffle(seed=42).select(range(2000)),
eval_dataset=dataset["test"].select(range(500))
)
trainer.train()
if __name__ == "__main__":
main()This script:
- Loads the IMDb dataset
- Tokenizes and batches it
- Fine-tunes a BERT model
- Saves the trained model to the path GCP expects via AIP_MODEL_DIR
GCP Vertex AI Command (with Preemptible GPU)
gcloud ai custom-jobs create \
--region=us-central1 \
--display-name=bert-training \
--python-package-uris=gs://your-bucket/bert_trainer-0.1.tar.gz \
--python-module=trainer.task \
--worker-pool-spec=machine-type=n1-standard-8,accelerator-type=NVIDIA_TESLA_T4,accelerator-count=1,replica-count=1This command:
- Tells GCP to run the training script using the resources specified
- Executes the main() in trainer.task
- Saves the model to gs://.../model/ or whichever directory Vertex AI writes to
Watch Out:
- GPU pricing in the cloud can spike for persistent workloads.
- Egress costs apply when moving data out of the cloud.
- Vendor lock-in limits portability and negotiation leverage.
On-Prem Infrastructure
On-premise AI infrastructure offers enterprises the highest level of control over their compute, data, and compliance posture. Unlike cloud environments, where you rent resources as services, an on-prem setup means owning and operating everything, from GPU servers to network topology. This model is often favored by organizations in regulated sectors such as finance, defense, or healthcare, where data residency, auditability, or latency requirements disqualify public cloud as the default option.
A typical on-prem enterprise AI strategy stack is built around Kubernetes, which orchestrates containers and workloads across GPU-enabled nodes. To make GPUs first-class citizens in Kubernetes, many teams deploy the NVIDIA GPU Operator, which automates the installation of drivers, monitoring tools, and Kubernetes device plugins.
For machine learning pipelines, Kubeflow is the most common choice. It lets teams define reusable training and evaluation pipelines, schedule distributed jobs, and monitor experiments, all inside the cluster. For observability, tools like Prometheus and Grafana are deployed natively, giving visibility into GPU utilization, training duration, and system health.
Here’s a minimal example of deploying a GPU-powered inference service inside your Kubernetes cluster:
apiVersion: v1
kind: Pod
metadata:
name: gpu-inference
spec:
containers:
- name: inference-server
image: yourregistry/inference:latest
resources:
limits:
nvidia.com/gpu: 1This tells Kubernetes to schedule the pod only on nodes with available GPUs. The node must already have the NVIDIA device plugin installed, typically managed by the GPU Operator.
While on-prem setups offer performance and compliance benefits, they come with operational tradeoffs. Scaling compute isn't instant, you can’t “spin up” four A100s like in the cloud. Hardware procurement cycles can take months. Lifecycle management, power and cooling, and DevOps staffing become core concerns. That said, for organizations with existing data center investments and GPU-intensive, long-running workloads, the tradeoff often makes sense.
Hybrid Infrastructure
Hybrid infrastructure is increasingly the default for large enterprises that want the agility of cloud combined with the security and control of on-prem. It doesn’t just mean “using both cloud and on-prem”, it means strategically splitting your AI workflow across environments to match their strengths.
A common hybrid pattern is to run model training in the cloud, where elastic GPU clusters can handle bursty compute loads efficiently, while deploying model inference on-prem, especially when data locality, latency, or regulatory constraints make it necessary.
For example, you might use AWS SageMaker to fine-tune a large language model on distributed spot GPU instances. Once trained, you export the model artifact and deploy it in an OpenShift cluster running on your internal infrastructure, optimized for real-time, low-latency inference.
CI/CD pipelines in a hybrid environment often use GitHub Actions to trigger deployments, with ArgoCD handling GitOps-based delivery across both cloud and on-prem Kubernetes clusters. Infrastructure is declared and versioned using Terraform, ensuring reproducibility across environments.
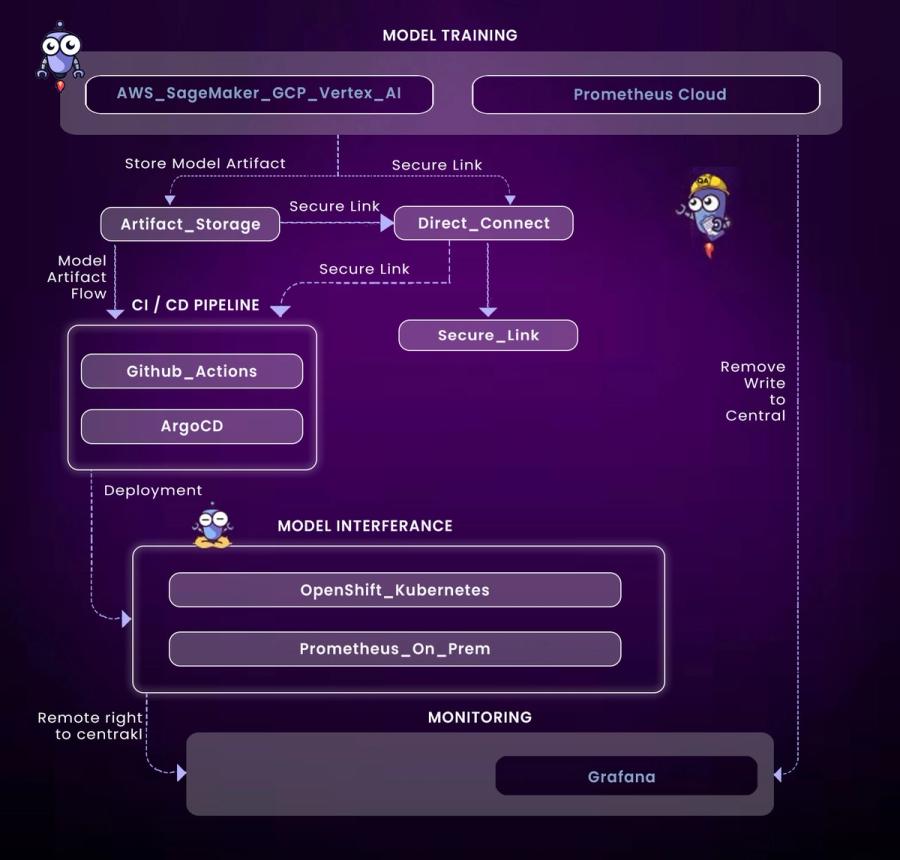
Hybrid Stack Example:
- Training (Cloud): Use AWS SageMaker or Vertex AI to train models using spot GPUs and distributed clusters.
- Inference (On-Prem): Serve the trained model on OpenShift, leveraging on-prem GPUs for real-time, low-latency inference.
- CI/CD:
- GitHub Actions for triggering pipelines
- ArgoCD for continuous deployment across cloud and on-prem clusters
- Terraform for infrastructure provisioning and version control
- Monitoring: Push metrics from on-prem Prometheus to a central observability backend using remote write.
Technical Criteria to Evaluate Before Choosing
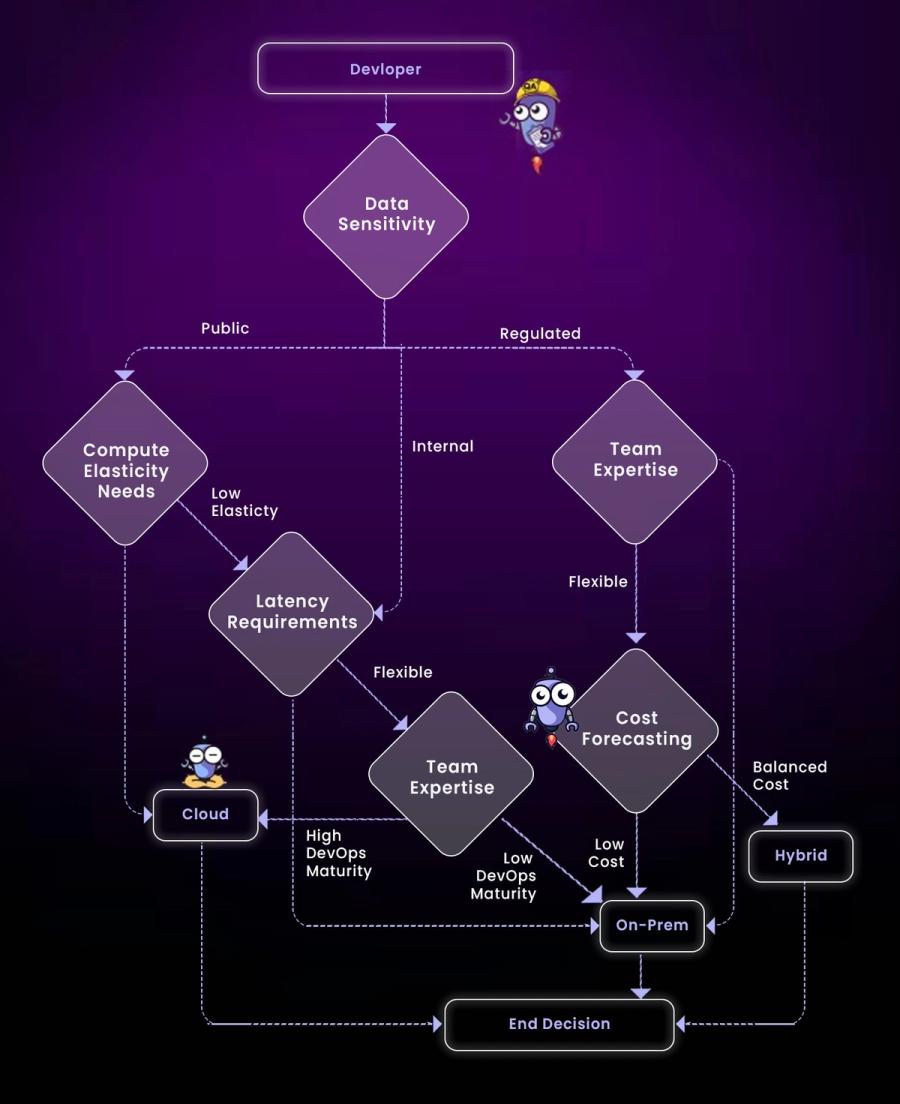
1. Workload Type
- Training: Spiky workloads, ideal for cloud or spot GPU usage.
- Inference: High QPS workloads require dedicated, low-latency compute (often on-prem).
- Pipelines: Streaming (Kafka), feature engineering, and transformation workloads often follow the data, not the model.
2. Data Gravity
Where your data resides dictates your enterprise AI strategy. Transferring large datasets from on-prem to cloud can incur both cost and latency.
Tip: Co-locate data pipelines and model training when possible.
3. Compliance Requirements
If you're handling:
- PHI (Protected Health Info)
- Financial transactions
- GDPR-covered PII
You may be legally required to process data on-premises or within a specific geography.
4. Cost Forecasting
Compare long-term costs using TCO models. For example:
GPU Compute (A100 x4):
- Cloud: $12,000 per month
- On-Prem (Amortized): $4,500 per month
Storage (10TB SSD):
- Cloud: $1,500 per month
- On-Prem (Amortized): $900 per month
Egress (5TB):
- Cloud: $400 per month
- On-Prem: $0
Management/Staffing Costs:
- Cloud: Low (managed services reduce staffing needs)
- On-Prem: High (requires dedicated infrastructure staff)
Conclusion
There’s no one-size-fits-all answer to enterprise AI strategy infrastructure. Cloud is agile but costly. On-prem is performant but rigid. Hybrid gives flexibility, but adds complexity. In this blog, we explored the core differences between cloud, on-prem, and hybrid models. Cloud infrastructure offers flexibility and rapid iteration, making it ideal for experimentation and burst training. On-prem setups provide full control, predictable performance, and better compliance alignment, especially for inference-heavy and regulated environments. Hybrid models bridge the gap, allowing organizations to train in the cloud and serve models or store data on-prem.
Make infrastructure decisions based on workload characteristics, data locality, compliance needs, and team maturity. Invest in modularity, automation, and visibility from the start to keep AI initiatives from becoming infrastructure nightmares.
FAQs
1. Can I Start In The Cloud And Migrate To On-Prem?
Yes. Containerization and IaC make phased migrations feasible. Tools like Anthos and OpenShift help bridge environments.
2. Do I Need GPUs For All Enterprise AI Strategy Workloads?
Not always. Use CPU for simple models and batch inference. Reserve GPU for training deep networks or LLM inference.
3. Is Hybrid Too Complex?
Hybrid does require strong DevOps capabilities but pays off for large orgs balancing cost, speed, and compliance.
4. Which Cloud Is Best For AI Workloads?
GCP is strong on AI tooling, AWS on GPU diversity and ecosystem, Azure on enterprise support. Choose based on your stack and org needs.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
