
Serverless MCP Server: Building Scalable Multi-Cloud Platforms without Managing Servers
Amit Eyal Govrin

TL;DR
- A control plane built with fully serverless components (like AWS Lambda, Step Functions, GCP Workflows) that manages multi-cloud infrastructure without running any servers.
- Eliminates persistent infrastructure costs, scales automatically, and simplifies ops for platform teams and MSPs managing across AWS, GCP, and Azure.
- API requests trigger serverless functions → functions execute provider-specific provisioning logic → workflows manage state → everything is event-driven and stateless.
- Key benefits include No VMs or clusters to manage, Pay-per-execution, zero idle cost, Native support for multi-cloud provisioning, Easy to integrate with portals like, ackstage or CI/CD pipelines.
- Best practices are Isolate logic per provider and service, Version APIs and workflows to support safe rollouts, Use DLQs, structured logging, and IAM boundaries, Abstract provider logic for extensibility, and Tag and monitor everything for cost visibility
- Ideal for internal developer platforms, SaaS control planes, self-service infra portals, and lightweight automation across clouds.
Let’s be honest, building a multi-cloud platform isn’t fun when you’re knee-deep in patching EC2 instances, managing Kubernetes upgrades, or untangling Terraform state files every week.
If you’re a platform engineer or part of a managed service provider (MSP) team, you’ve likely faced the pain of scaling infrastructure across AWS, GCP, and Azure. You need automation, consistency, and security, but the cost of running a full-blown control plane 24/7? That’s where it hurts.
Now imagine, what if your entire multi-cloud control logic ran without servers? No VMs, no clusters, just event-driven functions, API calls, and workflows. That’s the promise of a Serverless MCP Server.
In this guide, we’re going to break down what a Serverless MCP actually is, how it works, what it solves (and what it doesn’t), and how you can build one using real tools like AWS Lambda, Step Functions, and Terraform, all while keeping costs low and ops overhead close to zero.
What Is a Serverless MCP Server?
A Serverless MCP Server isn’t a “server” in the traditional sense. There's no EC2 instance, no Kubernetes cluster running in the background, and nothing you have to SSH into at 2 AM. Instead, it’s a fully event-driven control plane built entirely with managed, serverless components, like AWS Lambda, Step Functions, Google Workflows, and Azure Durable Functions. It acts as the brain behind your infrastructure automation, provisioning and orchestrating services across cloud providers like AWS, GCP, and Azure.
The core idea is to replace always-on, stateful systems with short-lived, stateless functions that react to incoming API requests, scheduled jobs, or infrastructure events. These functions execute provisioning logic, manage state transitions through orchestrators, and write operational metadata into managed databases like DynamoDB or Firestore, all without ever spinning up a server.

The concept of a serverless control plane can feel abstract, especially for teams used to managing persistent infrastructure like Kubernetes clusters or VM-based backends. In traditional environments, control logic is hosted on long-running systems that require ongoing patching, scaling, and monitoring. A serverless MCP takes a different approach: it moves that control logic into short-lived, stateless functions that only execute when triggered. There’s no always-on process. No infrastructure idling between requests. Provisioning logic, orchestration, and metadata handling are offloaded to fully managed services that scale with usage and disappear when idle. This model offers a practical alternative for teams that need multi-cloud automation without the burden of maintaining the automation layer itself.
How Does a Serverless MCP Server Work?
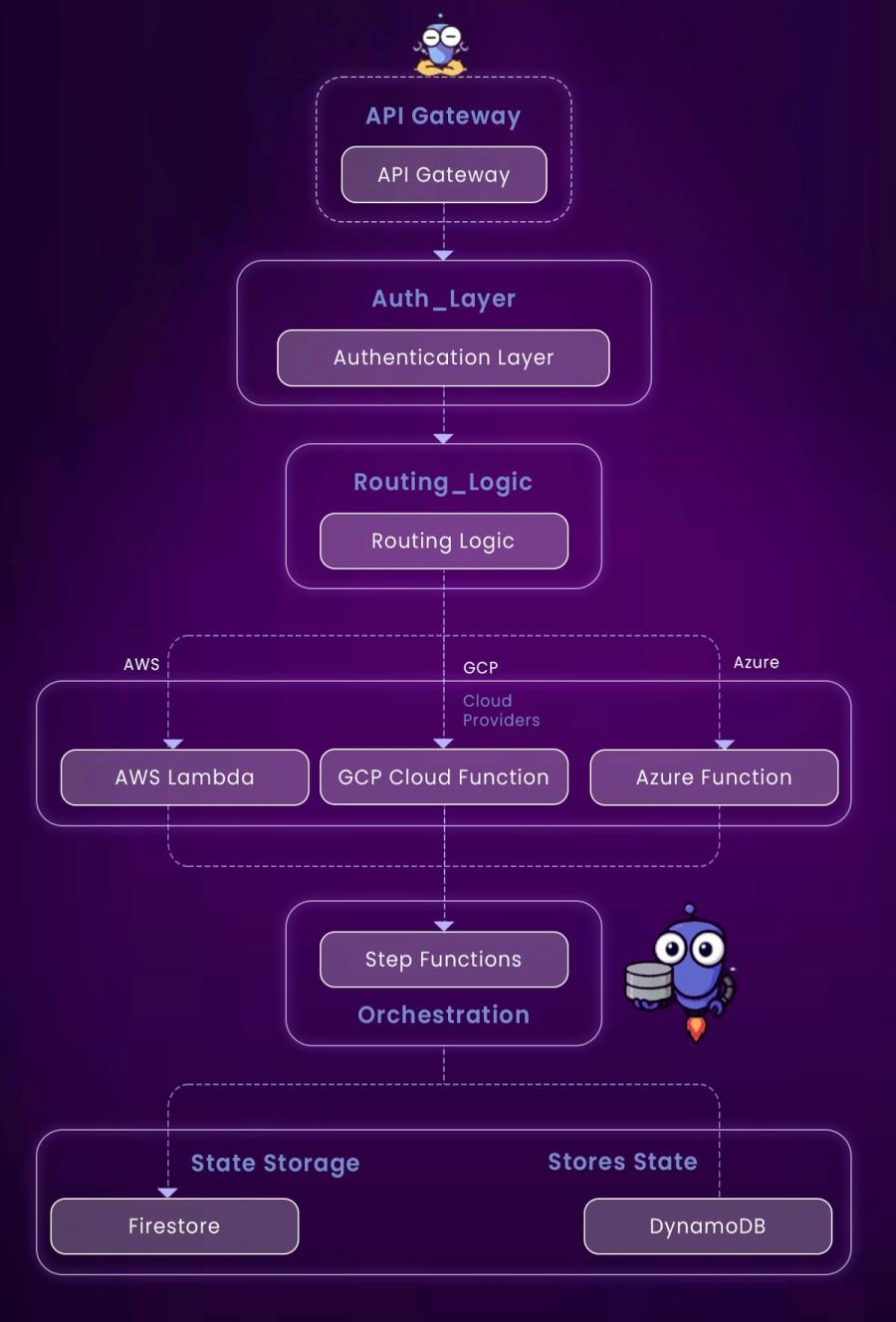
Let’s break it down in layers:
API Layer – Users or systems make HTTP requests via API Gateway, triggering provisioning workflows.
Auth Layer – Requests are authenticated using Cognito, Auth0, or JWT-based Lambda Authorizers.
Execution Layer – Cloud-specific logic is executed via Lambda (AWS), Cloud Functions (GCP), or Azure Functions.
State Management – Step Functions or Workflows manage multi-step processes; metadata is stored in DynamoDB or Firestore.
Event & Retry Layer – Queues (SQS, PubSub) and DLQs handle transient errors and async retries.
Why Go Serverless for MCPs?
Let’s compare serverless MCPs to traditional approaches:
| Feature | Traditional MCP | Serverless MCP |
|---|---|---|
| Infra Cost | High, constant | Zero idle cost |
| Ops Overhead | Needs patching, updates | Minimal (infra as config/code) |
| Scalability | Manual or auto-scale | Instant scale per invocation |
| API Latency | Low | Slightly higher (cold starts) |
| Abstraction Flexibility | Limited to stack | Easily extendable via code |
This model shines in scenarios where multi-tenant setups and cost-sensitive scaling are key.
Core Building Blocks of a Serverless MCP Server
1. API Layer
Every serverless MCP like AWS, Backstage, stateless mcp on lambda nodejs starts with an API layer, the public interface that external systems or internal teams interact with. Whether you're triggering workflows from a developer portal, CI pipeline, or Terraform module, everything flows through these gateways. On AWS, this often means API Gateway or AppSync; on GCP, Cloud Endpoints or Cloud Run with ingress controls; on Azure, API Management does the heavy lifting. These APIs expose routes like /provision or /terminate, secured with tokens or custom auth logic, and form the front door of your multi-cloud control plane.
2. Authentication and Authorization
Security isn’t bolted on, it’s built in. Before any provisioning logic runs, requests are validated against access policies and identity providers. Some teams use Lambda Authorizers for custom JWT validation and role scoping, while others integrate Cognito or Auth0 to handle user pools, scopes, and token issuance. The key here is tenant-level isolation and role-based access control. Every action, whether triggered by a developer or automation, should pass through a tightly scoped permission model. In multi-tenant setups, this is often tied directly to claims in the JWT, ensuring the provisioning logic can enforce strict access boundaries.
3. Provisioning Logic
Once authenticated, the provisioning logic takes over. This is the part that actually does the work, creating cloud resources, configuring access policies, generating credentials, tagging assets, and so on. Each cloud typically gets its own isolated handler. For example, a request for an AWS S3 bucket invokes a function wired into the AWS SDK; a GCP Cloud Run deployment might route to a different function entirely. These handlers are small, fast, and context-aware. They don’t hold global state, they operate on input payloads and environment variables, pulling secrets and config from services like SSM or Vault when needed.
4. Orchestration and Flow Control
Provisioning isn’t always a single-step operation. Many services require sequencing: create a network, then a compute resource, then apply firewall rules, possibly across multiple clouds. This is where orchestration comes in. AWS Step Functions, Google Workflows, and Azure Durable Functions let you define multi-step workflows as code. These orchestrators handle retries, branching, error catching, and manual approval steps. They give visibility into state transitions and allow teams to roll back or resume from failure without writing brittle procedural logic. And since they’re managed, there’s nothing to deploy or monitor beyond configuration.
5. State Management and Metadata
Every system needs a memory. In a serverless MCP, state is typically managed in DynamoDB, Firestore, or another schema-less, managed database. This layer stores provisioned resource IDs, their associated metadata, tags, ownership, and audit history. It’s also where workflow status can be persisted for future queries, especially useful for tracking things like “which services were provisioned for tenant A in environment B?” or “what’s the current status of this Step Function execution?” Because these databases scale automatically and support fine-grained access controls, they’re ideal for stateless functions that need persistent context without the overhead of traditional data layers.
Getting Started
Before diving into architecture, workflows, or CI/CD pipelines, the most important step is understanding what your MCP Server needs to do, and for whom. A Serverless MCP Server isn't a one-size-fits-all framework. It's a pattern, which you implement using your own provisioning logic, infrastructure tools, and cloud services. So getting started requires clarity around three things:
Define What You're Automating
Start by answering: “What should the MCP Server provision or manage?” It could be EC2 instances, VPCs, Kubernetes clusters, IAM roles, Cloud SQL instances, whatever your platform, MSP, or SaaS app needs to automate across cloud environments.
You don't need support for all services on day one. A simple starting point is one use case: provision an S3 bucket, deploy a GKE cluster, or create a secure VNet. Build a minimal, testable flow for a single provider.
Establish Your API Contract
The MCP Server exposes an HTTP interface, via API Gateway, Cloud Endpoints, or API Management, which external tools (Backstage, CI pipelines, internal CLI tools) will call. So define the request format it should accept and the actions it needs to support.
A minimal JSON schema looks like this:
{
"cloud": "aws",
"action": "provision",
"service": "s3",
"params": {
"bucketName": "project-assets",
"region": "us-east-1"
},
"tenant": "team-x",
"env": "dev"
}This becomes your contract, you’ll pass it to the Lambda handler or orchestrator, which then interprets the cloud, service, and action fields to decide what to run.
As your MCP evolves, version your API (/v1/provision, /v2/status) and gradually introduce typed schemas using JSON Schema, OpenAPI, or Zod.
Choose a Cloud and Deployment Stack
While the architecture is cloud-agnostic, AWS has the most mature primitives for event-driven provisioning (Lambda, Step Functions, IAM, API Gateway, DynamoDB). Start with AWS unless you're already deeply committed to another platform.
Use one of the following tools to scaffold:
- Serverless Framework: Best for bootstrapping fast
- AWS CDK (TypeScript or Python): Best for typed infra-as-code + logic
- Terraform: Great for teams already IaC-native, especially if multi-cloud
AWS also provides reference implementations to accelerate adoption. Start with the stateless-mcp-on-lambda-nodejs example, which includes:
- A REST API (POST /v1/provision)
- Per-cloud logic handlers (e.g., AWS provisioning)
- Structured logging and environment separation
- Deploy scripts using Serverless Framework
Fork it, modify the provisioning logic for your use case (e.g., spin up an S3 bucket or deploy a CloudFormation stack), and deploy it in your own AWS account.
Once you're comfortable with single-cloud flows, add GCP or Azure support using the same handler interface (CloudProvisioner.provision()), and route requests dynamically.
Once you're clear on what to provision and how it should be triggered, let’s move on to the How to Deploy a Serverless MCP Server section, where you’ll implement everything step-by-step, from API Gateway to Step Functions orchestration and CI/CD pipelines.

How to Deploy a Serverless MCP Server
Deploying a Serverless MCP Server means standing up a multi-cloud control plane using only managed, event-driven components, no clusters, no containers, and no persistent backends. Here's how to build and deploy one, assuming AWS as the base but extensible to GCP and Azure using the same primitives.
1. Define the Provisioning Contract
Start with an API contract that clearly defines how consumers will interact with the control plane. Each endpoint should accept a JSON payload like:
{
"cloud": "aws",
"action": "provision",
"service": "s3",
"params": {
"bucketName": "project-assets",
"region": "us-east-1"
},
"tenant": "team-x",
"env": "dev"
}This schema will be the input to Lambda functions and the orchestration layer. Structure it generically so you can extend it to other clouds later.
2. Set Up the API Gateway
Use Amazon API Gateway (HTTP API) to expose the entrypoint /v1/provision. You’ll need to:
- Configure a POST /v1/provision route
- Attach a Lambda integration
- Enable JWT validation using a custom Lambda Authorizer
- Define IAM permissions for the Gateway to invoke the Lambda
Example CloudFormation or CDK (TypeScript) snippet:
new HttpApi(this, 'McpApi', {
defaultAuthorizer: new HttpJwtAuthorizer({
jwtAudience: ['audience-id'],
jwtIssuer: 'https://cognito-idp.us-east-1.amazonaws.com/us-east-1_XXXX',
}),
routes: [
{
path: '/v1/provision',
methods: [HttpMethod.POST],
integration: new HttpLambdaIntegration('ProvisionHandler', provisionLambda),
}
]
});3. Create Cloud-Specific Lambda Handlers
Each cloud gets its own handler with no cross-provider logic. Here’s a simplified AWS example using Node.js and AWS SDK v3:
import { S3Client, CreateBucketCommand } from '@aws-sdk/client-s3';
export async function handler(event: any) {
const { params } = JSON.parse(event.body);
const client = new S3Client({ region: params.region });
await client.send(new CreateBucketCommand({ Bucket: params.bucketName }));
return { statusCode: 200, body: JSON.stringify({ status: 'provisioned' }) };
}You’ll build similar isolated handlers for GCP (@google-cloud SDK) and Azure (@azure/arm-*). Each should export a standardized interface:
interface CloudProvisioner {
provision(input: ProvisionRequest): Promise<ProvisionResponse>;
destroy(id: string): Promise<DeprovisionResponse>;
}This abstraction allows orchestration to remain cloud-agnostic.
4. Implement Step Functions for Workflow Orchestration
For multi-step provisioning (e.g., create network → VM → assign IP), use AWS Step Functions. Define each step as a Lambda task, with error handling and fallbacks:
{
"StartAt": "CreateVPC",
"States": {
"CreateVPC": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123:function:create-vpc",
"Next": "ProvisionEC2"
},
"ProvisionEC2": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123:function:provision-ec2",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "Rollback" }],
"End": true
},
"Rollback": {
"Type": "Fail"
}
}
}Use ASL (Amazon States Language) linting tools like asl-validator in CI to catch syntax or logic errors before deployment.
5. Store and Track State in DynamoDB
Provision a DynamoDB table to track every provisioning job:
aws dynamodb create-table \
--table-name ProvisioningJobs \
--attribute-definitions AttributeName=requestId,AttributeType=S \
--key-schema AttributeName=requestId,KeyType=HASH \
--billing-mode PAY_PER_REQUESTEach function in your workflow writes a status update to this table:
await ddb.send(new PutItemCommand({
TableName: 'ProvisioningJobs',
Item: {
requestId: { S: uuid },
tenant: { S: event.tenant },
status: { S: 'provisioning' },
timestamp: { S: new Date().toISOString() }
}
}));Use requestId as a correlation key throughout the system, including it in logs, API responses, and monitoring dashboards.
6. CI/CD Pipeline for Deployment
Set up GitHub Actions or GitLab CI to test and deploy the serverless MCP:
GitHub Actions Example:
jobs:
test-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install deps
run: npm install
- name: Lint
run: npm run lint
- name: Test
run: npm test
- name: Deploy
run: npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_KEY }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET }}
Alternatively, deploy infra using Terraform or CDK, with GitOps integrations via Spacelift or Atlantis.
Use Cases & Real-World Examples
Serverless MCP Servers are gaining traction across several types of infrastructure workflows from developer self-service to fully automated multi-cloud provisioning. Below are real scenarios where the pattern is not just conceptually useful but already in production-grade implementation.
1. Internal Developer Platforms
One of the most practical applications of a Serverless MCP is within internal developer platforms. In this model, the MCP server acts as the backend control plane that receives provisioning requests from UI-based tools like Backstage or Port. Instead of routing those requests to a monolithic backend, they’re sent to an API Gateway, triggering short-lived Lambda functions that execute cloud provisioning logic.
This exact design is captured in the stateless-mcp-on-lambda-nodejs reference from AWS. Requests are authenticated, routed, and executed across isolated handlers. The MCP doesn’t persist in any session state, every piece of context comes in the request payload and exits to a managed data store like DynamoDB.
2. Managed Service Providers (MSPs)
For MSPs managing multiple customer environments across clouds, the Serverless MCP pattern enables tenant-aware, isolated provisioning logic without any long-lived control plane. By isolating cloud-specific handlers into individual functions, teams can easily enforce per-tenant IAM boundaries, run logic conditionally based on customer metadata, and even track request-level cost.
This is how the AWS Serverless MCP is structured: it relies on AWS Lambda, Step Functions, and EventBridge to drive the entire provisioning pipeline. Each request passes through an API Gateway, gets authenticated via IAM or custom logic, and invokes a series of discrete tasks. Customers can be assigned individual pipelines, and every step is tracked with a correlation ID that flows through CloudWatch Logs and DynamoDB tables.
Conclusion
The Serverless MCP Server is a pragmatic, cost-efficient way to orchestrate infrastructure across multiple clouds without carrying the traditional operational burden. It’s built on event-driven serverless components, enforces clean service boundaries, and eliminates idle cost, it only runs when it’s needed.
For platform teams and MSPs, this architecture unlocks a flexible control layer that can be exposed internally through portals like Backstage or externally as a programmable API. It centralizes provisioning logic, improves security with tenant-aware execution, and scales on demand without maintaining a backend.
If you're a developer using an internal platform powered by a Serverless MCP, you get faster, more consistent provisioning, without waiting on tickets or manual ops. Your infrastructure requests (whether it’s a new database, a sandbox environment, or an S3 bucket) are fulfilled in seconds, with predictable results and real-time feedback.
If you're a customer of a SaaS product or a client of an MSP, this pattern ensures that infrastructure behind your features is provisioned securely, reliably, and instantly, even across different cloud providers, without downtime or provisioning delays.
Ultimately, Serverless MCP Servers reduce wait time, improve reliability, and make infrastructure feel like an API: available, self-service, and invisible when it’s not in use.
FAQ
1. Is this pattern production-ready?
Yes, many MSPs and internal platforms are already using this in production, with appropriate safeguards.
2. What are the downsides?
Cold starts, cloud lock-in (if you don’t abstract properly), and complexity when debugging distributed workflows.
3. Can this integrate with Backstage?
Yes. Use Backstage’s catalog-info.yaml + custom plugins to trigger serverless workflows via API.
4. What about security in multi-tenant setups?
Isolate users via JWT scopes or claims, and enforce access in your logic per request.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
