
What is AI Agent Orchestration
Amit Eyal Govrin

TL;DR
- AI Agent Orchestration = coordinating multiple specialized AI agents to complete complex tasks collaboratively.
- Each agent handles a specific domain (e.g., Terraform, GitHub, CI/CD) while the ai orchestrator routes tasks and manages state.
- Kubiya enables orchestration in DevOps environments via natural language inside Slack or Teams.
- Users can say things like: “Create a dev environment for Project X” → Kubiya triggers Terraform, validates changes, handles approvals, and notifies the team.
- Key components include - LLM-powered reasonin, Modular agent framework, Shared memory & context, Secure execution environment, RBAC, audit logging, and secret management.
- Benefits are Reduces need for manual scripts or hardcoded pipelines, Enables self-service ops for devs, Maintains governance and compliance, Scales infra workflows without scaling humans
- Ideal for DevOps, platform engineering, and teams looking to automate safely and intelligently across toolchains.
As engineering organizations scale, automation becomes essential, but automation scripts, Terraform pipelines, and CI/CD workflows still depend on humans to connect the dots. That’s where AI agent orchestration steps in.
Unlike brittle scripts or rule-based bots, AI agents operate with autonomy. They don’t just execute steps, they make decisions based on goals. In this post, we’ll explore what AI orchestration actually means for DevOps and infrastructure teams, using Kubiya as the lens.
What is AI Agent Orchestration?
AI agent orchestration refers to the coordination of multiple goal-oriented, reasoning-driven agents that work together to complete complex tasks, without being explicitly told how.
Think of it as having a team of junior engineers (agents), each specializing in a domain (like Terraform, GitHub, or AWS), collaborating to solve a problem based on high-level intent.
- AI Agent: Task-aware, LLM-powered, can reason and adapt.
- Orchestration: Dynamically assigning, sequencing, and managing multiple agents toward a desired outcome.
This is fundamentally different from:
- Chatbots: Pattern-matching Q&A with no autonomy.
- Scripts: Rigid logic with no adaptability.
- RPA: UI automation tools without contextual understanding.
For example: “Spin up a staging environment” might involve provisioning infra (Terraform), configuring IAM roles (AWS), deploying services (CI/CD), and notifying users (Slack). Orchestration coordinates these pieces without the user stitching them together manually.
Where Kubiya Fits In
Kubiya is an AI agent orchestration platform purpose-built for DevOps workflows. It sits inside your Slack workspace and bridges the gap between infra tools and natural language.
What makes Kubiya different?
- Goal-driven: Users don’t need to know the exact steps. Just say what you want.
- Context-aware: It remembers past interactions, org structure, approval policies, etc.
- DevOps-native: Works directly with tools like Terraform, GitHub, PagerDuty, AWS, and Jenkins.
- Secure: Follows RBAC, respects audit policies, integrates with identity providers.
It’s not just a Slack bot with scripts, it’s an orchestration layer for LLM agents that operate safely inside platform engineering environments.

How Agent Orchestration Works in Practice
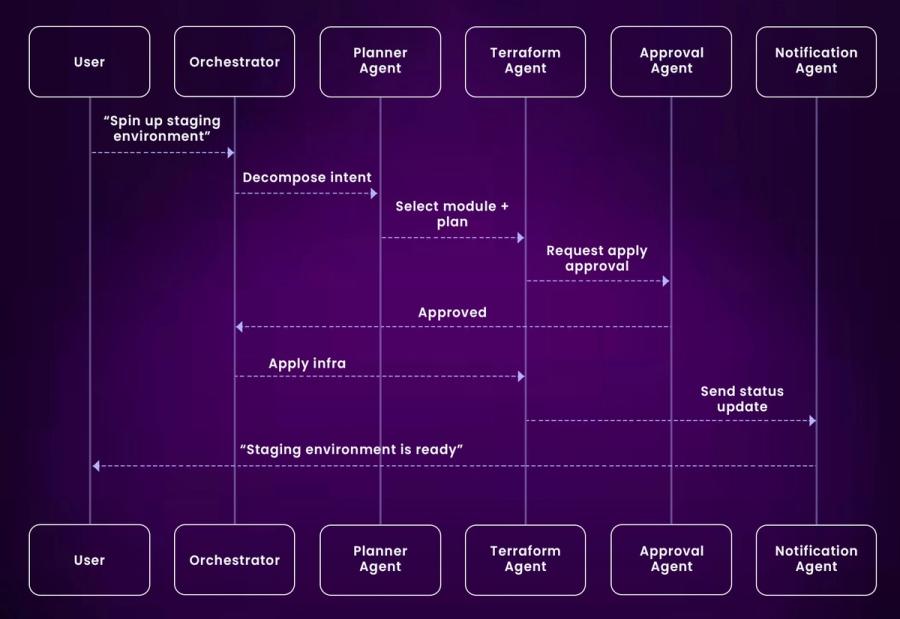
Let’s break down the lifecycle of an orchestrated agent workflow:
1. User Intent: A user types, “Create a dev environment for Project Delta.”
2. Intent Mapping: A Planning Agent determines the goal, what tools and steps are needed.
3. Sub-agent Invocation:
- Terraform Agent selects the relevant config and runs a plan.
- GitHub Agent checks for existing infra changes.
- Approval Agent checks if a human reviewer is needed.
4. Feedback Loop: Agents report back progress in Slack, collect missing variables, ask for confirmation.
5. Completion: Kubiya reports success, logs the activity, and links to the infra audit trail.
Unlike traditional workflows, these agents maintain state, adjust to missing inputs, and handle retries gracefully.
Real-World Use Case with Kubiya
Use Case: Provisioning a Cloud Resource with AI Agent Orchestration
Request:
“Spin up a new QA environment with Node.js stack.”
A developer types this simple instruction into Slack. It’s vague but high-level, the kind of thing a human SRE would understand from context. But for an AI system to act on it reliably, the orchestration engine must extract intent, fill in gaps, validate inputs, and coordinate safe execution.
Step 1: Parsing Intent and Extracting Context
The orchestrator’s LLM component (e.g., GPT-4 or Claude) interprets the natural language request. It identifies three key pieces of information:
Environment Type: “QA”, Tech Stack: “Node.js”, Desired Action: “Spin up” (i.e., provision infrastructure).
Kubiya also checks prior history in the conversation and workspace configuration. For instance, if the developer has previously worked on a project called checkout-service, it may infer that this request relates to that same project unless told otherwise.
Step 2: Selecting the Right Terraform Module
Next, the orchestrator forwards the task to the Terraform Agent, which is scoped to infrastructure provisioning. This agent pulls from a library of vetted Terraform modules (e.g., qa_env_nodejs.tf) that follow internal standards for things like naming, tagging, security groups, and cloud cost limits.
The agent selects the correct module using the identified stack (Node.js), the target environment (QA), the calling user’s permissions (RBAC policies), predefined guardrails (e.g., no public IPs in non-prod).
Step 3: Interactive Parameter Resolution
Before execution, Kubiya checks if all required variables are present. If not, it asks for specifics directly inside Slack using dynamic forms or follow-up questions region: “Which AWS region should this QA environment be deployed to?”, instance type: “Do you want the default t3.medium or a custom instance class?”, and feature flags: “Should monitoring and autoscaling be enabled?”
This conversational layer ensures no assumptions are made, helping maintain clarity and preventing costly misconfigurations.
Step 4: Secure Execution and Real-Time Updates
Once all parameters are resolved and validated, Kubiya triggers the Terraform plan followed by apply, using a secure runner with scoped credentials. This execution is logged with full traceability (user ID, inputs, outputs), sandboxed to ensure it only affects the permitted environment and connected to Slack for visibility
Kubiya posts live status updates in the same Slack thread plan passed, apply in progress (10% complete...), and environment ready, access it at qa.checkout-service.internal.
Why It Matters
This use case shows the true power of AI agent orchestration: it transforms vague human requests into deterministic, auditable, and production-safe infrastructure actions, without requiring developers to know CLI syntax, YAML configs, or Terraform internals. Instead of submitting a ticket or pinging DevOps, teams can move faster—with confidence and control baked in.
Under the Hood: What Powers Kubiya
While Kubiya presents a simple, Slack-native interface, there’s significant technical complexity beneath the surface. It acts as a middleware that connects natural language input to infrastructure operations, without compromising control or observability.
Let’s unpack the key architectural components:
1. LLM Backbone
Kubiya uses large language models like OpenAI’s GPT-4 or Anthropic’s Claude to interpret user intent, reason through multi-step tasks, and generate dynamic workflows.
Example: A user types:
“Rollback the last deployment on project-x in staging.”
Instead of triggering a pre-written script, the LLM interprets what “project-x” maps to in the deployment system, what the “last deployment” refers to (e.g., the most recent Git SHA or Helm release). How to find the rollback command in your toolchain (e.g., Argo CD, GitHub Actions, Jenkins).
This level of reasoning can't be captured by static scripts alone, it requires semantic understanding, tool awareness, and runtime decision-making.
2. Agent Framework
Kubiya decomposes tasks into specialized modular agents, each designed to interact with a specific system or domain.
These include:
- Terraform Agent: Runs plan, apply, and fetches outputs.
- GitHub Agent: Opens PRs, checks branch status, reads diffs.
- Shell Agent: Executes controlled CLI commands in sandboxes.
- PagerDuty Agent: Looks up on-call engineers, creates incidents.
- Jira Agent: Creates, updates, and links to existing tickets.
Example: To “increase memory limits in dev pods”, Kubiya may use the GitHub Agent to locate the correct Helm values file, modify memory fields using context-aware suggestions and commit the change via PR and request review from the right team.
Agents can also collaborate. A Planning Agent may invoke a Shell Agent to validate output, then pass it to a Notification Agent for delivery.
3. Memory + Context Store
Kubiya maintains persistent memory scoped to users, channels, projects, and workspaces, allowing it to retain context across different interactions. For example, if a user says, “Create a new sandbox like the one I made last week,” Kubiya can recall which project was involved, which Terraform module and input variables were used, and even that the user preferred us-east-2 as the default AWS region.
This context retention is especially valuable in environments like Slack, where conversations are often fragmented and asynchronous. By remembering past actions and preferences, Kubiya can seamlessly continue workflows across time and users without requiring redundant explanations or manual reconfiguration.
4. Execution Environment
All agent tasks eventually map to system actions, CLI commands, API calls, Terraform runs, etc. These are executed inside secure, isolated environments with scoped permissions.
Kubiya supports docker-based runners, Remote runners via SSH, Kubernetes job invokers, and third-party integrations (e.g., GitHub Actions)
Example: A Terraform apply task will Validate the plan in a container, use injected credentials via secrets manager, and post the diff back in Slack with approval buttons.
This design isolates the control plane (LLM + agent coordination) from the execution layer, keeping critical actions auditable and tamper-resistant.
5. Policy Engine
Kubiya embeds a lightweight policy engine to govern agent behavior. Features include RBAC checks before invoking any task, rate limits to prevent accidental loops or overuse, Token budgets to cap LLM usage per org or workspace and escalation workflows if approvals or interventions are required.
Example: A junior engineer requests a production deployment. Policy engine checks:
- User role → no direct prod access.
- Task type → high-risk.
- Workflow → forward to senior engineer for Slack-based approval.
This ensures AI-driven workflows still follow human-set boundaries.

Security and Governance
Kubiya’s multi-agent orchestration model brings automation closer to natural language, but that doesn’t mean compromising on control, auditing, or compliance. Here’s how it stays safe in enterprise environments:
1. RBAC + SSO Integration
Kubiya integrates with identity providers like Okta, Azure Active Directory, GitHub Teams, Custom SAML/LDAP systems. Access control is enforced at the agent and task level.
2. Scoped Permissions
Kubiya enforces workspace-scoped access. Each workspace has its own toolchain config (e.g., AWS creds, GitHub repos), restricts which agents and actions are allowed and can define custom prompts, variables, and workflows.
This scoping prevents accidental or malicious cross-project access.
3. Audit Trails
Every action Kubiya performs, every prompt, tool invocation, CLI run, and response, is logged with full metadata.
Logs will include who initiated the task. What agents were invoked. Which tools were used. Execution timestamps and outputs.
These logs can be streamed to SIEM systems (Splunk, Datadog), Cloud logging backends (CloudWatch, GCP Logging), Internal audit portals.
4. Secrets Management
Kubiya doesn’t expose secrets inside Slack conversations. Credentials and tokens are managed securely via:
- HashiCorp Vault
- AWS Secrets Manager
- Kubernetes Secrets
Agents retrieve secrets at runtime and inject them into isolated environments, without displaying or storing them in LLM context windows.
Example:Even if a user asks, “What’s the AWS root token?” , the LLM is restricted from accessing any such environment variable or secret via static and dynamic policies.
Why Scripts and CI Pipelines Aren’t Enough
Infrastructure as Code and CI/CD are essential, but still brittle when you need flexibility or reasoning because you need to remember command syntax or file paths. Hard to connect tools (e.g., pull from GitHub, run Terraform, send Slack alert). No adaptive decision-making based on changing inputs.
Agentic workflows introduce goals > tasks:
“Fix the staging environment crash” becomes → diagnose logs → check resource health → redeploy service → notify on-call.
It bridges the gap between ops and automation, without needing every edge case hardcoded.
Setting Up a Basic Kubiya Workflow
Connect Slack
1. Invite Kubiya to your Slack.
2. Define default workspace context (e.g., AWS account, repo).
3. Grant it access to necessary channels.
Define a Workflow Task
task:
name: Create Dev Env
inputs:
- project
- region
steps:
- terraform_plan:
file: ./environments/dev/main.tf
- approval_required:
approvers: platform-team
- terraform_apply: trueConfigure Access Controls
- Create RBAC policies (only DevOps team can deploy to prod).
- Set approval rules by task type or environment.
Common Pitfalls and Limitations
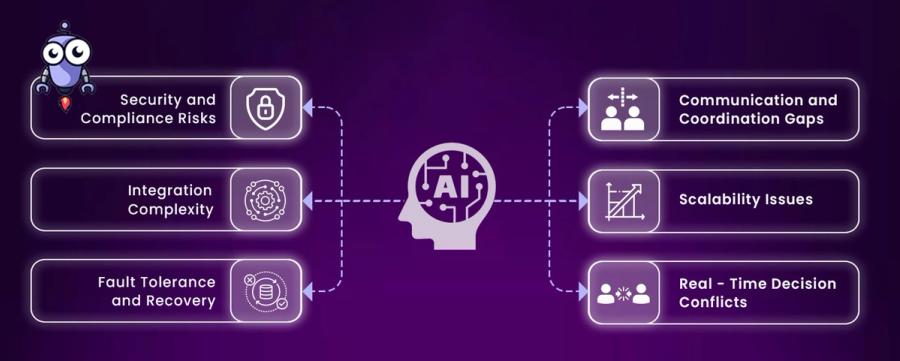
No tool is magic, and AI agents come with caveats:
LLM Limitations
Hallucinations are real, require fallback validation or human-in-the-loop.
Latency
Multi-agent workflows aren’t always fast; task orchestration adds time.
Context Limits
Long sessions can hit token limits, and need to manage memory state efficiently.
Complex Debugging
Understanding why an agent made a decision can be tricky without good logging.
Conclusion
AI agent orchestration isn’t a replacement for engineers, it’s a smarter way to scale automation without scaling headcount.
Kubiya offers a pragmatic approach: don’t build agents from scratch; use pre-configured, infra-native agents inside your developer workflows. It allows teams to shift from “run this script” to “achieve this goal”, while staying secure and governed.
For DevOps and platform teams drowning in tooling and process debt, orchestrated agents offer a way to unify workflows, enforce guardrails, and deliver self-service infrastructure, all through natural language.
FAQs
1. What is AI Agent Orchestration?
A coordinated system managing multiple specialized AI agents working together to achieve complex objectives, rather than relying on one general-purpose AI. Each agent is responsible for a clear task, while the orchestration layer manages roles, data flow, task assignment, and handoffs.
2. Why is orchestration important compared to single-agent systems?
Single-agent systems become unwieldy as use cases grow, they’re hard to debug, expand, or maintain. Orchestration splits logic across modular agents, improving maintainability, scalability, and resilience.
3. How does AI agent orchestration work in practice?
AI agent orchestration begins by breaking a complex task into logical, manageable segments, each aligned to a specific role such as planning, execution, validation, or communication. Once the task is decomposed, the orchestrator either assigns prebuilt agents or integrates custom ones tailored to each function. For instance, a research agent might pull logs, while a remediation agent runs infrastructure fixes.
4. What are the different orchestration patterns?
There are several distinct patterns used in AI agent orchestration, depending on the system's complexity and control requirements. In a centralized pattern, a single orchestrator maintains full control over agent actions. In hierarchical orchestration, a top-level orchestrator delegates responsibility to subsystem orchestrators, each managing their own agents.
About the author
Amit Eyal Govrin
Amit oversaw strategic DevOps partnerships at AWS as he repeatedly encountered industry leading DevOps companies struggling with similar pain-points: the Self-Service developer platforms they have created are only as effective as their end user experience. In other words, self-service is not a given.
